Ok, I fixed the issue I was having. I'm not really sure what the issue was, but it appears to be gone after a few modifications to the offending code. I can't really say I'm happy about the outcome. I haven't really changed anything fundamental, and I don't even know what the problem was in the first place.
Since I'm sure you're riveted to your seats, wondering what the bug was, I'll tell you. Maybe you can tell me what the cause was. When I changed the path of the program, it crashed. That is, the compiled program would work in the directory I compiled it to, no issues. But change the name of the directory the executable was in, or copy the directory to a different location (keeping the relative paths of the resources intact) and it would fail. Madness.
I did do a couple of things in the program that weren't very nice. I had a nested for loop and I needed to keep track of how many times I run the inner loop, so I declared a variable outside of the loop and incremented it inside the loop, as an index into a dynamically allocated array, then used it again outside after increasing it a couple of times.
The big change I did was not to use it outside the loop. My best guess is I was incrementing it by one more than the size of the array outside the loop, and overwriting some bit of memory that I shouldn't have been messing with. How that could possibly cause the program to work in the compilation directory but not when I changed it's name, I may never know. But then, that's what happens when you play with arrays, and one of the reason to avoid them when possible.
Unfortunately, OpenGL calls want you to give them raw pointers to arrays. I am doing well enough using smart pointers instead, but until I wrap them up in safer structures, some dangers remain. I should look into using vector, I think it might help. I'm just not sure I can get the pointer to the memory, or that vector has to pack the information in a certain manner. Arrays are ugly, but at least I have control over the packing of the bits in there, and that's what I need.
Now that it's working, however, I'm can get to working on something more important. Currently I'm using a noise function that unfortunately I can't easily reinitialize. Basically, I need to add a 'shuffle' function to rearrange the values in an array, which serves as the seed of the noise generator. Shouldn't be too difficult.
EDIT - Curse you, Skyrim! I'm afraid I got slightly sidetracked this past week. Good thing this scheduling thing works.
Monday, November 21, 2011
Monday, November 14, 2011
Giving shape to the world
I finally have an interesting playground to experiment in, so it's about time I focused on what I wanted to do in the first place. The main drive behind this project was procedural content, making use of algorithms to populate the world with variety instead of a fixed number of precomputed models. I've already been doing that, in fact. The distribution of spheres in the demo, for example, and their size, is all deterministically decided by the program at run time.
All I do is decide how many spheres I want, what the range of sizes should be, and the volume of space to use. The program then fills the space. Because the starting conditions are always the same, the program always builds the same scene. I could easily create a different distribution by changing the seed or any of the parameters. I want to go further, though. Right now, all these spheres are kind of boring. And not very asteroid like. To change this, I'll deform the spheres to create more interesting shapes.
My initial plan is to assign each sphere a height map. I'll then use the height map to raise or lower away from the center of the sphere each vertex. One difficulty I expect is how to adjust the normals as the terrain is reshaped, but I'll figure something out. On the height map end, I'll use the simplex noise algorithms I've talked about before to give each asteroid a distinct look. By seeding each asteroid with a distinct value, I ensure they'll all be unique.
For the height map, I only need it to match one pixel to a vertex. This way I can send the value to the vertex shader as an attribute. I already created the spheres using a gridlike pattern, so I can use the uv coordinates of each pixel for this purpose. This does mean that there will be more detail near the poles that along the equator, but because my source is going to be a 3d density function it should not result in any obvious distortions. The output will go into a Vertex Buffer Object, which will be fed to the video card and called when drawing.
Normally, height maps add a height to points on a grid, which is level with either the XZ or XY planes, meaning Z or Y is treated as height, and that value is replaced with the value of the height map. However, I have a sphere. On a sphere, height is defined as the distance from the center. To apply the height map to a sphere, I have to work a bit more.
The values I have will fall between -1 and 1. If I do straight multiplication of the surface point by the value, I'd have a mess. Instead, what I do is decide what I want the range of heights to be. If I want the highest points to jut out three times the radius of the sphere, for example, and the deepest valleys to reach half way to the center of the sphere, that gives me a range of (3 - 0.5 ) = 2.5 radius. The half point (where the height map is 0) would be 1.25 radius, so I could get the position of every point as ( (1+height)*1.25 + 0.5) * position.
The other complex bit is recalculating the normals. By changing the shape of the sphere, the surface normals all change as well and that impacts the light on each point. If I don't get them right, the lighting will look decidedly odd.
That's getting ahead of me a bit. First I need to be sure I can produce the information and get it into the shader. I had to add an extra attribute to the Model class to do it, but after a few short tweaks I got it up and running. What I'm doing right now is using the height value of each point as a color value, with -1 being black and 1 being white. So higher areas will look brighter.
It's working, and I'm pretty happy about that. I'm now struggling with an odd problem; when running the project from a pendrive it works, but copying the project to the hard drive and running it there doesn't. Fixing that is probably going to give me enough for another post itself.
All I do is decide how many spheres I want, what the range of sizes should be, and the volume of space to use. The program then fills the space. Because the starting conditions are always the same, the program always builds the same scene. I could easily create a different distribution by changing the seed or any of the parameters. I want to go further, though. Right now, all these spheres are kind of boring. And not very asteroid like. To change this, I'll deform the spheres to create more interesting shapes.
My initial plan is to assign each sphere a height map. I'll then use the height map to raise or lower away from the center of the sphere each vertex. One difficulty I expect is how to adjust the normals as the terrain is reshaped, but I'll figure something out. On the height map end, I'll use the simplex noise algorithms I've talked about before to give each asteroid a distinct look. By seeding each asteroid with a distinct value, I ensure they'll all be unique.
 |
| A sample of simplex noise |
For the height map, I only need it to match one pixel to a vertex. This way I can send the value to the vertex shader as an attribute. I already created the spheres using a gridlike pattern, so I can use the uv coordinates of each pixel for this purpose. This does mean that there will be more detail near the poles that along the equator, but because my source is going to be a 3d density function it should not result in any obvious distortions. The output will go into a Vertex Buffer Object, which will be fed to the video card and called when drawing.
Normally, height maps add a height to points on a grid, which is level with either the XZ or XY planes, meaning Z or Y is treated as height, and that value is replaced with the value of the height map. However, I have a sphere. On a sphere, height is defined as the distance from the center. To apply the height map to a sphere, I have to work a bit more.
The values I have will fall between -1 and 1. If I do straight multiplication of the surface point by the value, I'd have a mess. Instead, what I do is decide what I want the range of heights to be. If I want the highest points to jut out three times the radius of the sphere, for example, and the deepest valleys to reach half way to the center of the sphere, that gives me a range of (3 - 0.5 ) = 2.5 radius. The half point (where the height map is 0) would be 1.25 radius, so I could get the position of every point as ( (1+height)*1.25 + 0.5) * position.
The other complex bit is recalculating the normals. By changing the shape of the sphere, the surface normals all change as well and that impacts the light on each point. If I don't get them right, the lighting will look decidedly odd.
That's getting ahead of me a bit. First I need to be sure I can produce the information and get it into the shader. I had to add an extra attribute to the Model class to do it, but after a few short tweaks I got it up and running. What I'm doing right now is using the height value of each point as a color value, with -1 being black and 1 being white. So higher areas will look brighter.
 |
| Looks nicer than blue with red and green dots. |
It's working, and I'm pretty happy about that. I'm now struggling with an odd problem; when running the project from a pendrive it works, but copying the project to the hard drive and running it there doesn't. Fixing that is probably going to give me enough for another post itself.
Monday, November 7, 2011
Looking good. Looking real good.
Well, that was quite a bit of wait between updates, but lighting is done. Sort of.
It's helpful for me to see what I need to do to flesh the shaders out. Later on I'll need to add textures, and shadows, and multiple sources of light. The nice thing about space shooters, though, is that you generally only have one big source of light to worry about. Certainly, there is plenty of room for lighting effects all over, but what's going to be illuminating the planets, asteroids and ships for the most part is the big star in the middle.
A concern I'm having is that as I add features, the code is getting a more unwieldy. For the most part I've avoided a serious case of spaghetification, but I really should spend some time consolidating certain pieces of code. Before I do that, however, I want to have a better feel for what works and what doesn't in my design.
I've already identified some decisions that weren't the best. For example, my use of inheritance would in many cases be better suited to templates. I wanted to avoid templates, because they are somewhat arcane in their workings, but already my use of the standard and boost libraries has me working with them. I feel more confident now about using them, and it would simplify some things.
This means I'm going to have to do a bit of a rewrite of several big chunks. Rewrites aren't fun, but on the positive side I'm not going to be starting from zero. That seems like a good opportunity to reassess and redesign, so I want to get a bit more experience in before I undertake that particular task. It's a fragile balance I have to manage between having enough features in there that I know how to design it better and having so much that redesigning it is too daunting to do.
It doesn't help that work has picked up and I'm generally too burned out to focus on this when I get home. That's also part of why I've let the update schedule slip, for which I apologize.
In the interest of making things easier for everyone, I've switched back from 7z to zip files to share the program. 7z was a necessity when I was sharing the program through gmail. Mail programs don't like zipped executable files, and having people rename a file from .jpg to .exe to get around it was more trouble than convincing them to use 7zip. But with the files now hosted in Google Docs, I can go use zip files again.
As always, the folder is Framework Releases, and the project itself is Framework-0.0.8.
It's helpful for me to see what I need to do to flesh the shaders out. Later on I'll need to add textures, and shadows, and multiple sources of light. The nice thing about space shooters, though, is that you generally only have one big source of light to worry about. Certainly, there is plenty of room for lighting effects all over, but what's going to be illuminating the planets, asteroids and ships for the most part is the big star in the middle.
A concern I'm having is that as I add features, the code is getting a more unwieldy. For the most part I've avoided a serious case of spaghetification, but I really should spend some time consolidating certain pieces of code. Before I do that, however, I want to have a better feel for what works and what doesn't in my design.
I've already identified some decisions that weren't the best. For example, my use of inheritance would in many cases be better suited to templates. I wanted to avoid templates, because they are somewhat arcane in their workings, but already my use of the standard and boost libraries has me working with them. I feel more confident now about using them, and it would simplify some things.
This means I'm going to have to do a bit of a rewrite of several big chunks. Rewrites aren't fun, but on the positive side I'm not going to be starting from zero. That seems like a good opportunity to reassess and redesign, so I want to get a bit more experience in before I undertake that particular task. It's a fragile balance I have to manage between having enough features in there that I know how to design it better and having so much that redesigning it is too daunting to do.
It doesn't help that work has picked up and I'm generally too burned out to focus on this when I get home. That's also part of why I've let the update schedule slip, for which I apologize.
In the interest of making things easier for everyone, I've switched back from 7z to zip files to share the program. 7z was a necessity when I was sharing the program through gmail. Mail programs don't like zipped executable files, and having people rename a file from .jpg to .exe to get around it was more trouble than convincing them to use 7zip. But with the files now hosted in Google Docs, I can go use zip files again.
As always, the folder is Framework Releases, and the project itself is Framework-0.0.8.
Saturday, November 5, 2011
An apology and an explanation
I've spent the past week wrangling with an annoying bug in the code. Turned out to be a simple mistake, but since the lighting code was all new I had to go over it with a fine-toothed comb until I figured out what was wrong. Fixing it was simple enough, but it took me a while. It didn't help that I had a particularly busy month.
As the days passed and it seemed like I would miss my deadline, I had to make a choice. Either release what I had, knowing it was buggy, or let the week pass. I had the post already done, and I could fix the demo in the meantime. I had already slipped into posting on Wednesdays while doing the lighting bit, and I didn't want to completely miss the week.
However, the philosophy of releasing for a deadline, not when it is working, is one of the things I dislike about the programming industry. Seeing as this is something I'm doing for myself, I want it to be done right and follow my own ideals.
One of these ideals is releasing with no known bugs. No program more complex than 'Hello World' is ever bug free, but it's one thing for your users to find bugs, and a very different thing for you to release a bug you know about into the wild. Releasing with the expectation of a patch later is the reason why so much stuff works as badly as it does.
The downside is that if I'm planning to make a release and just missing the demo, a bug that takes too long to fix (an amount of time fundamentally unpredictable) will throw my schedule off and leave me with nothing to post. I do have to apologize for that. I should work on building a buffer of some sort, although that's a bit difficult as what I usually do is write about what I'm doing at the time.
On the other hand, planning what I'll work on with more time can only help avoid these issues.
The bug is fixed, the demo is working, and I'm now working on the focus for the next part. I have scheduled the post with the explanation of the demo to go up at 9:00 GMT on Monday, so as to go back to my regular release day. In the meantime, the demo is up in Google Docs already.
As always, the folder is Framework Releases, and the project itself is Framework-0.0.8. I switched to zip files to make things simpler for everyone.
As the days passed and it seemed like I would miss my deadline, I had to make a choice. Either release what I had, knowing it was buggy, or let the week pass. I had the post already done, and I could fix the demo in the meantime. I had already slipped into posting on Wednesdays while doing the lighting bit, and I didn't want to completely miss the week.
 |
| Really didn't want to be tardy |
One of these ideals is releasing with no known bugs. No program more complex than 'Hello World' is ever bug free, but it's one thing for your users to find bugs, and a very different thing for you to release a bug you know about into the wild. Releasing with the expectation of a patch later is the reason why so much stuff works as badly as it does.
The downside is that if I'm planning to make a release and just missing the demo, a bug that takes too long to fix (an amount of time fundamentally unpredictable) will throw my schedule off and leave me with nothing to post. I do have to apologize for that. I should work on building a buffer of some sort, although that's a bit difficult as what I usually do is write about what I'm doing at the time.
On the other hand, planning what I'll work on with more time can only help avoid these issues.
The bug is fixed, the demo is working, and I'm now working on the focus for the next part. I have scheduled the post with the explanation of the demo to go up at 9:00 GMT on Monday, so as to go back to my regular release day. In the meantime, the demo is up in Google Docs already.
As always, the folder is Framework Releases, and the project itself is Framework-0.0.8. I switched to zip files to make things simpler for everyone.
"I am NOT Tardy" Image by MidoriFlygon
Wednesday, October 26, 2011
Let there be light!
Now that I have a little playground with some basic physics, controls and the like, we can worry a little more about the downright dreadful appearance of the place. Everything looks flat, because I'm slapping solid colors with no shading at all.
Shading helps give a sense of depth, and even the most basic techniques would result in a much improved look and feel. Naturally then, we need to start thinking about lighting. What I'll be implementing for the following stretch is something called the ADS lighting model, which stands for Ambient, Diffuse and Specular.
According to this model, the color that we see an object have is the result of adding three contributions from the light that's lighting it up. These are the ambient light, the diffuse light and the specular light.
Ambient light is the result of light that has bounced several times between objects, with the result that there is no identifiable source. It results in a general brightening of an object, essentially a flat color boost to everything. If we only had ambient light, we'd get a picture much like what I already have.
Diffuse light is what produces the natural shading we are used to. This light comes from a source, and the angle between the source and the surface normal determines how brightly lit it is. A surface placed perpendicular to a light source will be illuminated more brightly than one placed at an angle, and as a result will have a brighter color. Surfaces parallel or looking away from the light source, on the other hand, are not illuminated at all.
Finally, specular light describes how shiny a surface is, creating the highlights caused by the light source. While Ambient and Difuse lighting depend solely on the position of the light source, Specular light also depends on the position of the observer.
Adding all these together would give the result we want. In order to add it I don't really have to mess much with the program code, which is fortunate. The heavy lifting is going to be done in the shader program. The actual program is just going to have to provide the necessary information.
Next week I should have a first implementation of it running.
 |
| What a solid red sphere would look like in the program |
According to this model, the color that we see an object have is the result of adding three contributions from the light that's lighting it up. These are the ambient light, the diffuse light and the specular light.
Ambient light is the result of light that has bounced several times between objects, with the result that there is no identifiable source. It results in a general brightening of an object, essentially a flat color boost to everything. If we only had ambient light, we'd get a picture much like what I already have.
 |
| Ambient light illuminating a red sphere |
 |
| Diffuse light. Paint doesn't have a gradient tool. Use your imagination. |
Finally, specular light describes how shiny a surface is, creating the highlights caused by the light source. While Ambient and Difuse lighting depend solely on the position of the light source, Specular light also depends on the position of the observer.
 |
| Specular lighting is highly focused. As the observer moves, the apparent position of the highlight can also move. |
Adding all these together would give the result we want. In order to add it I don't really have to mess much with the program code, which is fortunate. The heavy lifting is going to be done in the shader program. The actual program is just going to have to provide the necessary information.
Next week I should have a first implementation of it running.
Wednesday, October 19, 2011
Collision Detection - Appendix A - Collisions
Not much to report this week. Work was busy, leaving little time for important stuff. Still, I don't want to let the week pass with no updates over here, so I decided to share some of the stuff I didn't go into detail before.
For starters, how I'm actually resolving the collisions. It's still a bit buggy, so writing it down might help me figure out what is wrong.
As I said in the first part, I'm doing elastic collisions between spheres. If I was making a billiards game, this would be all I really need. Upon detecting a collision, as I said, I determine the position when the two objects first touch by moving them back in time until the distance to their centers is the sum of their radii. Basically multiply their speed by a negative number and add it to their positions.
Next I need to calculate their new speeds. In order to do this, it's helpful to move ourselves into a convenient reference frame. It's often the case in physics problems that you can get halfway to a solution just by changing how you look at it. In my case, all speeds and positions are stored relative to a frame of reference where all the spheres are initially at rest, and the origin is where the player first appears.
This means that the first collision will always be between an object at rest and one moving. Further collisions may be between moving objects, with no reasonable expectation of any relationship between their movements. Instead of this, we'll move the collision to the reference frame of the center of mass of the two colliding objects.
This has certain advantages; in an elastic collision, the speed of the center of mass before the collision and after the collision will not change. From the center of mass, the collision looks as if two objects approached each other, hit, and then moved away, regardless of what their speed in the standard reference frame is. Their respective speeds depend on the relationship between their masses, as well.
For example, consider two spheres of equal mass, one at rest and the other rolling to hit it head on. From the center of mass, it looks as if the two spheres approach, each moving at half the speed of the original sphere in the original frame of reference, meet at the center, and then their speeds where reflected off each other. From the original reference frame, it looks as if the first sphere stops and the sphere that was at rest moves away at the speed of the first sphere.
From the point of view of the center of mass, if the masses were different the larger mass would appear to move more slowly, and when they bounce it would move away more slowly as well.
This is fairly straightforward for head on collisions, but far more often collisions are slightly off-center. For these, we need to apply a little more thought. Still, the same rules apply. The main difference is that we need to reflect the speeds by the angle of the collision surface, the plane tangent to both spheres at the collision point.
In order to do this we need to know the normal of the collision surface, which is simple enough as it is the normalized vector that joins the center of both spheres. In our example the masses are equal, which means that in order for the center of mass to remain static the speeds must be equal and opposite, and this relationship must be maintained after the collision as well.
The equation to reflect the speed vectors is
Vect2 = Vect1 - 2 * CollisionNormal * dot(CollisionNormal,Vect1)
This must be applied to both bodies, of course.
We can see that the situation of both bodies crashing into each other is actually a special case of the off-centre collision, as we would expect. The dot product of the speed vector and the collision normal in that case is the length of the speed vector, since the dot product can be considered the projection of one vector on the other, and both vectors share the same direction.
Multiplying the length of the speed vector by a normalized vector in the same direction yields the original speed vector, and when subtracted twice from the original vector we end with a vector of the same length and opposite direction, which is what happens in head on collisions.
In off-center collisions, the effect is that we reverse the component of the speed along the collision direction, and leave the perpendicular component intact. The more glancing a blow is, the greater the angle between the collision direction and the speed direction, resulting in a smaller speed component along that axis and as a consequence a smaller deflection.
For starters, how I'm actually resolving the collisions. It's still a bit buggy, so writing it down might help me figure out what is wrong.
As I said in the first part, I'm doing elastic collisions between spheres. If I was making a billiards game, this would be all I really need. Upon detecting a collision, as I said, I determine the position when the two objects first touch by moving them back in time until the distance to their centers is the sum of their radii. Basically multiply their speed by a negative number and add it to their positions.
Next I need to calculate their new speeds. In order to do this, it's helpful to move ourselves into a convenient reference frame. It's often the case in physics problems that you can get halfway to a solution just by changing how you look at it. In my case, all speeds and positions are stored relative to a frame of reference where all the spheres are initially at rest, and the origin is where the player first appears.
This means that the first collision will always be between an object at rest and one moving. Further collisions may be between moving objects, with no reasonable expectation of any relationship between their movements. Instead of this, we'll move the collision to the reference frame of the center of mass of the two colliding objects.
This has certain advantages; in an elastic collision, the speed of the center of mass before the collision and after the collision will not change. From the center of mass, the collision looks as if two objects approached each other, hit, and then moved away, regardless of what their speed in the standard reference frame is. Their respective speeds depend on the relationship between their masses, as well.
For example, consider two spheres of equal mass, one at rest and the other rolling to hit it head on. From the center of mass, it looks as if the two spheres approach, each moving at half the speed of the original sphere in the original frame of reference, meet at the center, and then their speeds where reflected off each other. From the original reference frame, it looks as if the first sphere stops and the sphere that was at rest moves away at the speed of the first sphere.
 |
| The angle of the green line represents the movement of the center of mass through the three stages of the collision. |
From the point of view of the center of mass, if the masses were different the larger mass would appear to move more slowly, and when they bounce it would move away more slowly as well.
This is fairly straightforward for head on collisions, but far more often collisions are slightly off-center. For these, we need to apply a little more thought. Still, the same rules apply. The main difference is that we need to reflect the speeds by the angle of the collision surface, the plane tangent to both spheres at the collision point.
In order to do this we need to know the normal of the collision surface, which is simple enough as it is the normalized vector that joins the center of both spheres. In our example the masses are equal, which means that in order for the center of mass to remain static the speeds must be equal and opposite, and this relationship must be maintained after the collision as well.
 |
| Off-center collision showing speed vectors, collision plane and normal. |
The equation to reflect the speed vectors is
Vect2 = Vect1 - 2 * CollisionNormal * dot(CollisionNormal,Vect1)
This must be applied to both bodies, of course.
We can see that the situation of both bodies crashing into each other is actually a special case of the off-centre collision, as we would expect. The dot product of the speed vector and the collision normal in that case is the length of the speed vector, since the dot product can be considered the projection of one vector on the other, and both vectors share the same direction.
Multiplying the length of the speed vector by a normalized vector in the same direction yields the original speed vector, and when subtracted twice from the original vector we end with a vector of the same length and opposite direction, which is what happens in head on collisions.
In off-center collisions, the effect is that we reverse the component of the speed along the collision direction, and leave the perpendicular component intact. The more glancing a blow is, the greater the angle between the collision direction and the speed direction, resulting in a smaller speed component along that axis and as a consequence a smaller deflection.
Monday, October 10, 2011
Collision Detection - Part 3 - Space Partitioning
In the previous two parts I walked through my own implementation of collision detection and resolution, a pretty basic one at that. You can find a working demo of everything I described here: Framework-0.0.7.
As I was saying last time, however, this method of comparing everything to everything has a problem. The number of collision tests required grows with the square of the number of items. This severly limits the number of elements that can fit in a scene. It should not be too noticeable in the demo, but once I add better shaders. more complex models and more game logic it all starts adding up.
It's also just plain wasteful to check things we know can't collide. The question lies in how to make the computer aware of this. That's where space partitioning comes in.
Consider a surface with a set of scattered circles. My current method would have me compare every object to every object. For the case of say, fifty circles, that would require 1,225 checks. However, we know that the objects on the far sides of the surface can't possibly touch each other. So we split the surface in two, so that each half contains twenty-five objects, and run the collision detection on each half independently.
Using the formula from before, (n-1)*n/2, we determine that each half now requires 300 checks, for a total of 600 checks for both sides. With just splitting the space once, we've halved the required number of checks. We can go further, of course. If we split the space in four, leaving thirteen objects in each quarter(rounding up), we will require 78 checks per quarter. A total of 312 checks.
Split the space again, into eights, so that each contains seven elements. The required number of checks is then 21 per partition, or 168 total. How low can we go? Let's say we split the space in 32 areas, each with 2 elements. We only need one check to make sure two objects aren't touching. The total would then be 32 checks. That's a considerable decrease from the original scenario, about a fortieth of the number of required checks.
The goal, then would seem to be to split the space until we have as few elements in each area as possible. However, for this example, I took the liberty of assuming the circles were all uniformly distributed, and would fill all the areas without leaving gaps. In reality, as they move and bounce about, the density of circles in a given area will change unpredictably. If we draw a fixed grid, there's no way to guarantee that they won't all find their way into the same spot.
We could try making the grid very fine, to limit the likelyhood of many elements occupying one at once, but that means that we have a great number of areas, many of which may well be empty. We have to go through each and every cell to check how many objects it has, so we want to avoid empty cells as much as posible, since they add to our overhead. Furthermore, if the cells are very small, the likelyhood of a single circle occupying several cells increases. For a given grid, a circle could fit in between one and four cells, provided the cells are as large as the circle.
There is an additional overhead that space partitioning brings, in that you have to keep the grid updated. It's easy enough to determine what grid an object belongs to, but we want to traverse the grid, not the object list. That means that each time an object moves, we need to keep track of wether or not it changed cells. We can at least get rid of empty cells, and avoid checking cells with just one element.
There is a way to avoid some of the problems with grids, however, through the use of structures called quadtrees (in 2D) and their extension in 3D, octrees. These are complex enough to require a post of their own. The important thing is that we can see how, through the use of space partitioning, we can cut down the time consuming issue of collision detection into something more manageable.
As I was saying last time, however, this method of comparing everything to everything has a problem. The number of collision tests required grows with the square of the number of items. This severly limits the number of elements that can fit in a scene. It should not be too noticeable in the demo, but once I add better shaders. more complex models and more game logic it all starts adding up.
It's also just plain wasteful to check things we know can't collide. The question lies in how to make the computer aware of this. That's where space partitioning comes in.
Consider a surface with a set of scattered circles. My current method would have me compare every object to every object. For the case of say, fifty circles, that would require 1,225 checks. However, we know that the objects on the far sides of the surface can't possibly touch each other. So we split the surface in two, so that each half contains twenty-five objects, and run the collision detection on each half independently.
 |
| Each line represents one required pairwise check. Doubling from three to six elements increased the required checks five times, from three to fifteen. |
Split the space again, into eights, so that each contains seven elements. The required number of checks is then 21 per partition, or 168 total. How low can we go? Let's say we split the space in 32 areas, each with 2 elements. We only need one check to make sure two objects aren't touching. The total would then be 32 checks. That's a considerable decrease from the original scenario, about a fortieth of the number of required checks.
The goal, then would seem to be to split the space until we have as few elements in each area as possible. However, for this example, I took the liberty of assuming the circles were all uniformly distributed, and would fill all the areas without leaving gaps. In reality, as they move and bounce about, the density of circles in a given area will change unpredictably. If we draw a fixed grid, there's no way to guarantee that they won't all find their way into the same spot.
We could try making the grid very fine, to limit the likelyhood of many elements occupying one at once, but that means that we have a great number of areas, many of which may well be empty. We have to go through each and every cell to check how many objects it has, so we want to avoid empty cells as much as posible, since they add to our overhead. Furthermore, if the cells are very small, the likelyhood of a single circle occupying several cells increases. For a given grid, a circle could fit in between one and four cells, provided the cells are as large as the circle.
There is an additional overhead that space partitioning brings, in that you have to keep the grid updated. It's easy enough to determine what grid an object belongs to, but we want to traverse the grid, not the object list. That means that each time an object moves, we need to keep track of wether or not it changed cells. We can at least get rid of empty cells, and avoid checking cells with just one element.
There is a way to avoid some of the problems with grids, however, through the use of structures called quadtrees (in 2D) and their extension in 3D, octrees. These are complex enough to require a post of their own. The important thing is that we can see how, through the use of space partitioning, we can cut down the time consuming issue of collision detection into something more manageable.
Monday, October 3, 2011
Collision Detection - Part 2 - Resolution
Last week, I talked a bit about how to detect collisions. I didn't go into too much detail, focusing on first order approaches to limit the number of tests we have to do. There are multiple ways of getting increasingly tighter results, such as a hierarchy of bounding volumes. The way it works is you split the body into a series of smaller bounding volumes, such that the whole object is contained within them. Properly built, you can discard half the triangles in a body on each level, until you find the intersection.
But that's beyond the scope of my first attempt. I'm going to be pretending that my bodies are all perfectly round, and handle the crashes accordingly. The result is that the first order check with spherical bounding volumes gives me all the information I need.
After comparing the bodies' distance from each other, I have a list of all the collisions that happened in a given frame. This should be a fairly small list. It's unlikely that in a given frame you'll find many collisions. Still, we don't want to assume we'll only ever find one, or we may find strange results in some cases.
Of course, after going to all this trouble to determine when two objects are getting too close, we actually have to decide what to do about it. This decision has to be informed by the kind of game, and the actors involved. For example, if you detect the collision between a bullet and an object, you'll want to remove the bullet and deal damage to the object. If you are simulating billiard balls, you'll want to have them bounce off of each other. If it's a person walking into a wall, you might just want to move them back so they're not inside the wall any more and stop them.
I'm going to be pretending my 'asteroids' act as billiard balls for now. This means elastic collisions. It won't look very good when the asteroids gain better detail, but by then we can improved the tests in different ways.
Starting with the collision list, we can determine how long ago each crash was. We know the distance between the bodies and their speeds. The difference between the sum of their radii and their actual distance divided by their relative speeds tells us the time since they crashed. We can then back up the simulation to the first crash by reversing the speed of the objects and moving them to the positions they would have been in at the time of the crash.
Once this is done, we calculate the new speeds, using simple collision physics. There's plenty of information on how to do this on the internet, so I won't go into the details. It doesn't really add to the subject in any case, the important thing is that the math gives us new speeds for the objects involved. We now advance the simulation to the time we were at before backing up, and run the collision detection again.
I don't actually use the old list because when we changed the velocities of the objects, we changed things in such a way that we can't be sure that that collision happened. Or it may be that the new velocities caused another collision. The only way to be sure is to run the collision detection again. Since the frames should really be very quick, we shouldn't find too many collisions on a single frame. Objects would have to be very tightly packed for this to be a concern, such as in the opening shot of a billiard game.
Still, this can get expensive. Worse still, the way I'm doing things, adding elements to the scene increases the cost very quickly. We can even determine exactly how much more expensive each additional item is. One object requires no checks. Two objects require one check. Three objects require three checks. Four will require six checks. Five will require ten checks. And in general, n objects will require (n-1)*n/2 checks. This is a quadratic function, and something we don't really want to work with. Having just fifty objects in the scene would require 1,225 checks every frame. Double or triple if we have a few impacts.
There is of course a way about this problem as well, which I'll talk about next week.
But that's beyond the scope of my first attempt. I'm going to be pretending that my bodies are all perfectly round, and handle the crashes accordingly. The result is that the first order check with spherical bounding volumes gives me all the information I need.
After comparing the bodies' distance from each other, I have a list of all the collisions that happened in a given frame. This should be a fairly small list. It's unlikely that in a given frame you'll find many collisions. Still, we don't want to assume we'll only ever find one, or we may find strange results in some cases.
Of course, after going to all this trouble to determine when two objects are getting too close, we actually have to decide what to do about it. This decision has to be informed by the kind of game, and the actors involved. For example, if you detect the collision between a bullet and an object, you'll want to remove the bullet and deal damage to the object. If you are simulating billiard balls, you'll want to have them bounce off of each other. If it's a person walking into a wall, you might just want to move them back so they're not inside the wall any more and stop them.
I'm going to be pretending my 'asteroids' act as billiard balls for now. This means elastic collisions. It won't look very good when the asteroids gain better detail, but by then we can improved the tests in different ways.
Starting with the collision list, we can determine how long ago each crash was. We know the distance between the bodies and their speeds. The difference between the sum of their radii and their actual distance divided by their relative speeds tells us the time since they crashed. We can then back up the simulation to the first crash by reversing the speed of the objects and moving them to the positions they would have been in at the time of the crash.
Once this is done, we calculate the new speeds, using simple collision physics. There's plenty of information on how to do this on the internet, so I won't go into the details. It doesn't really add to the subject in any case, the important thing is that the math gives us new speeds for the objects involved. We now advance the simulation to the time we were at before backing up, and run the collision detection again.
I don't actually use the old list because when we changed the velocities of the objects, we changed things in such a way that we can't be sure that that collision happened. Or it may be that the new velocities caused another collision. The only way to be sure is to run the collision detection again. Since the frames should really be very quick, we shouldn't find too many collisions on a single frame. Objects would have to be very tightly packed for this to be a concern, such as in the opening shot of a billiard game.
Still, this can get expensive. Worse still, the way I'm doing things, adding elements to the scene increases the cost very quickly. We can even determine exactly how much more expensive each additional item is. One object requires no checks. Two objects require one check. Three objects require three checks. Four will require six checks. Five will require ten checks. And in general, n objects will require (n-1)*n/2 checks. This is a quadratic function, and something we don't really want to work with. Having just fifty objects in the scene would require 1,225 checks every frame. Double or triple if we have a few impacts.
There is of course a way about this problem as well, which I'll talk about next week.
Monday, September 26, 2011
Collision Detection - Part 1 - Detecting it
I apologize for the tardiness. Should have had this up last Monday. Never decided on an official update schedule, but I think Monday is a good day for it.
So, what have I been so busy that I couldn't post? Well, I've been trying to wrangle with Collision. If you've tested the last demo I put out, you might have noticed that things go through each other, including the player. That's because I haven't included any logic in the loop that looks for objects interacting. I essentially create the spheres and player ship, and draw them, but they're each doing their own thing.
Collision detection (and resolution) is about finding when these objects interact, and how. The clearest example is not letting objects go through each other. But it's also necessary for detecting bullets hitting targets and damaging them, and objects bouncing believably when they hit something.
This is a complex problem, but thankfully computers today are very powerful machines. Collisions on a scale unthinkable years ago can run on current hardware in real time. There's a great deal of studying that has gone into sorting this problem as well, both for research in scientific applications and in the video game industry looking for more realistic behaviors.
The first issue we find is how to determine that there was, indeed, a collision. There are many ways that this can be done, from checking every triangle in a model to every other triangle in the scene (where intersecting triangles identify a collision) to comparing bounding volumes, and ways of speeding up the process itself by culling impossible scenarios.
The way I chose to start with is essentially the simplest (and given my field of spheres, one that should work just fine). I create a bounding volume around each object. A bounding volume is a three dimensional shape built around an object that guarantees that no point in the object lies outside of the volume. Take a square, for example. A circle centered on the square and with a diameter at least as wide as either diagonal bounds the square, since all four points would lie inside it.
In my case, I'm using spheres as the bounding volume. I can center these on the entity, and size them so that they have the same size of the model (in the case of the spheres, for the ship the sphere is a bit bigger than it really needs to be). The idea behind the bounding volumes isn't to find if two objects intersect, but to be able to discard those that don't.
Comparing bounding volumes is faster and easier than comparing the models themselves, triangle to triangle. Since the volumes completely enclose the model, we know that if the two volumes don't meet there is no way for the models to meet, and we can discard the entire models at once instead of making sure triangle by triangle. Checking if two spheres intersect is a trivial check if you know their centers and their respective radii: If the distance between the centers is less than the sum of their radii, the spheres intersect. Else, they don't.
While we can guarantee that if the spheres don't intersect the models don't either (and we can then avoid checking further), it's not necessarily true that if they intersect the models are touching. Thus, it's possible (even expected) that the bounding volume method may yield "false positives", resulting in collisions when two objects aren't touching. The solution is to do a more expensive check, triangle against triangle for example, on these. The advantage is that by excluding the ones we know can't intersect with a cheap check, we save a considerable amount of computing power.
Other bounding volumes commonly used are AABBs and OBBs, which stand for Axis Aligned Bounding Box and Oriented Bounding Box. Both consist of building boxes around the models, with the difference that the OBB builds the smallest box that the model fits in and rotates it together with the model, while the AABB builds the smallest box that can align to the world coordinate system. If the object within an AABB changes orientation, the AABB must be recalculated.
The advantage the boxes have is that they produce fewer false positives than a sphere. Spheres leave too much empty volume, especially the less 'round' the object within it is. Consider a stick, for example. In such a case, where one dimension of the object is much larger than the other two, the sphere will be mostly empty and any objects passing through this empty space will need to be checked against the stick, resulting in wasted computation.
The second easiest volume to check is the AABB. To see if two volumes intersect, one must simply check the sides. It's simplified because they are aligned to the axis, so that the x,y or z values along each side are fixed. On the other hand, building the volume each time the model changes orientation can get expensive. In the case of the stick, for example, we find ourselves in pretty much the same situation as the sphere is it is oriented away from all three axis, and get the best results if lies along any one of them.
The OBB method, finally, guarantees the fewest false positives. Finding the smallest OBB can be a bit expensive, but it needs only be done once when you create the model. On the other hand, comparing OBBs to find intersections is more expensive than either of the previous methods.
There really isn't a 'best method', as they all have their own costs which need to be considered. AABBs are good for scenery, for example, which doesn't change orientation. On the other hand, if you have a roundish object, a sphere will produce less wasted space than either box method. The good thing is we don't need to 'choose' a single method, as for very little overhead we can implement box-sphere checks that let us mix things up.
Further, the bounding volume is only the first test. And as large and complex as models have become, it's not uncommon for there being a hierarchy of checks that are run, cutting the amount of triangle test required down to sane levels. With two ten thousand polygon models, for example, just checking one against the other would be too much wasted time.
Whew. That took more than I thought. Don't really have the time to fish for pictures though.
No new demo today, but soon. Next Monday: what happens when you find an intersection!
So, what have I been so busy that I couldn't post? Well, I've been trying to wrangle with Collision. If you've tested the last demo I put out, you might have noticed that things go through each other, including the player. That's because I haven't included any logic in the loop that looks for objects interacting. I essentially create the spheres and player ship, and draw them, but they're each doing their own thing.
Collision detection (and resolution) is about finding when these objects interact, and how. The clearest example is not letting objects go through each other. But it's also necessary for detecting bullets hitting targets and damaging them, and objects bouncing believably when they hit something.
This is a complex problem, but thankfully computers today are very powerful machines. Collisions on a scale unthinkable years ago can run on current hardware in real time. There's a great deal of studying that has gone into sorting this problem as well, both for research in scientific applications and in the video game industry looking for more realistic behaviors.
The first issue we find is how to determine that there was, indeed, a collision. There are many ways that this can be done, from checking every triangle in a model to every other triangle in the scene (where intersecting triangles identify a collision) to comparing bounding volumes, and ways of speeding up the process itself by culling impossible scenarios.
The way I chose to start with is essentially the simplest (and given my field of spheres, one that should work just fine). I create a bounding volume around each object. A bounding volume is a three dimensional shape built around an object that guarantees that no point in the object lies outside of the volume. Take a square, for example. A circle centered on the square and with a diameter at least as wide as either diagonal bounds the square, since all four points would lie inside it.
In my case, I'm using spheres as the bounding volume. I can center these on the entity, and size them so that they have the same size of the model (in the case of the spheres, for the ship the sphere is a bit bigger than it really needs to be). The idea behind the bounding volumes isn't to find if two objects intersect, but to be able to discard those that don't.
Comparing bounding volumes is faster and easier than comparing the models themselves, triangle to triangle. Since the volumes completely enclose the model, we know that if the two volumes don't meet there is no way for the models to meet, and we can discard the entire models at once instead of making sure triangle by triangle. Checking if two spheres intersect is a trivial check if you know their centers and their respective radii: If the distance between the centers is less than the sum of their radii, the spheres intersect. Else, they don't.
While we can guarantee that if the spheres don't intersect the models don't either (and we can then avoid checking further), it's not necessarily true that if they intersect the models are touching. Thus, it's possible (even expected) that the bounding volume method may yield "false positives", resulting in collisions when two objects aren't touching. The solution is to do a more expensive check, triangle against triangle for example, on these. The advantage is that by excluding the ones we know can't intersect with a cheap check, we save a considerable amount of computing power.
Other bounding volumes commonly used are AABBs and OBBs, which stand for Axis Aligned Bounding Box and Oriented Bounding Box. Both consist of building boxes around the models, with the difference that the OBB builds the smallest box that the model fits in and rotates it together with the model, while the AABB builds the smallest box that can align to the world coordinate system. If the object within an AABB changes orientation, the AABB must be recalculated.
The advantage the boxes have is that they produce fewer false positives than a sphere. Spheres leave too much empty volume, especially the less 'round' the object within it is. Consider a stick, for example. In such a case, where one dimension of the object is much larger than the other two, the sphere will be mostly empty and any objects passing through this empty space will need to be checked against the stick, resulting in wasted computation.
The second easiest volume to check is the AABB. To see if two volumes intersect, one must simply check the sides. It's simplified because they are aligned to the axis, so that the x,y or z values along each side are fixed. On the other hand, building the volume each time the model changes orientation can get expensive. In the case of the stick, for example, we find ourselves in pretty much the same situation as the sphere is it is oriented away from all three axis, and get the best results if lies along any one of them.
The OBB method, finally, guarantees the fewest false positives. Finding the smallest OBB can be a bit expensive, but it needs only be done once when you create the model. On the other hand, comparing OBBs to find intersections is more expensive than either of the previous methods.
There really isn't a 'best method', as they all have their own costs which need to be considered. AABBs are good for scenery, for example, which doesn't change orientation. On the other hand, if you have a roundish object, a sphere will produce less wasted space than either box method. The good thing is we don't need to 'choose' a single method, as for very little overhead we can implement box-sphere checks that let us mix things up.
Further, the bounding volume is only the first test. And as large and complex as models have become, it's not uncommon for there being a hierarchy of checks that are run, cutting the amount of triangle test required down to sane levels. With two ten thousand polygon models, for example, just checking one against the other would be too much wasted time.
Whew. That took more than I thought. Don't really have the time to fish for pictures though.
No new demo today, but soon. Next Monday: what happens when you find an intersection!
Monday, September 12, 2011
It's full of stars!
I've gotten a few new features into the framework, such as a first implementation on 'shooting', but that's not what I want to talk about today.
So far, I've focused solely on functional details. Making models, making sure the models are displayed, movement, views and such. The result is... well, it's functional. Of course I want to have something good before I start polishing. A polished turd is still a turd, so I have to turn it into something else first.
The traditional way of making a background is making use of a skybox. This is basically a cube you draw around the scene. With the aid of something called cubemapping, you can slap the sky on the inside and the textures used fool the eye into thinking it's looking at a dome, rather than a cube. No seams or anything, if done correctly.
Of course, I didn't have the textures to make it look good handy.while there are plenty of images of space around, there's very few of a look at the complete sky, and those that are have fish eye effects. I could have slapped a few images, merged them together or something and called it a day, but I wanted something special.
So, I started a little side project. The idea being, I'd create the background out of a real galaxy I made up on the spot. This would mean create all the stars, jump into an appropriate position inside the galaxy and take pictures of what is visible in each direction. That way I would have the textures I needed for the cube map. I could scale the definition as much as I want, or move to a different spot and have the constelations in the background actually shift properly.
How to do it, though? A galaxy like our milky way has on the order of a hundred billion stars. Can't really draw them one at a time. Instead, my plan is to split the space the galaxy occupies into as many blocks as I can manage, and give it shape with the use of two functions.
One of the functions will give the galaxy a shape. The second will add some higher frequency noise to make it look more interesting.
I will represent the blocks with points, and once I have it all working try to improve the appearance. I really want the GPU to do the heavy lifting here. I can make a shader program that checks the position of each point and assigns it a value for each function, then multiplies them together. But if I tell the GPU to draw a million points one at a time, the overhead on the calls will slow things to a crawl. So what I do instead is make use of instanced drawing.
Instanced drawing means I tell the gpu to draw a singlemodel (in my case, as ingle point) as many times as I want. It's helpful for drawing many identical objects. The result, after setting the color to solid red, is not very impressive:
Of course, drawing several identical points means they get drawn in the same spot. In order to add variation, the gpu gives me an extra variable, an instance id, which I can manipulate for some interesting effects.
For my first test, I'm sending 0x1000 points to the gpu. That's 4096 in decimal, but you'll see why I work in hex in a bit. This means the instance ids range from 0x0 to 0xFFF (4095). What I can do is treat each of the hex digits as a coordinate in one of the axis, x, y and z, and move the point by that amount. So for example, the point 0x123 maps to position (1, 2, 3). I use bit masks and some bitwise arithmetic to work out the positions, which is why I do it this way. Computers, as you know, like binary and powers of 2 better than decimal.
Adding the instance id into the mix then, the result is a cube made of red dots. Not very impressinve right now, but it's a start.
I can play around with color too. For example, if I treat x as Red, y as Green and z as Blue, I get a colorful cube:

Ok, so back to the galaxy. First, I'll give it a proper shape. A cube is hardly the proper shape, so let's ignore points outside of a central sphere. For that, I'll give points further than 1 unit from the center a color of 0.1. There may be a few stragglers around the galaxy, but they're few and far between.

Much better. Now, galaxies tend to be shaped as disks, more than spheres, so we want to squash the sphere as well. What we want is to decrease the intensity with regards to the height from the plane. I'll use y to measure height from the plane, and to avoid the break being so obvious I'll also diminish the intensity along the diskthe farther you are from the center. The result:

Not so bad. Still need to add more features, though. For example, our galaxy has spiral arms. These will require a bit more thinking.
I didn't get quite as far as I meant to, mostly due to Deus Ex. Still, I don't want to leave you without an update so check out Framework-0.0.6r. You can do everything you could do before, and now shoot too! The space key now fires instead of accelerating, you accelerate with Left Shift. Fun* game to play: see how much you can shoot before it starts slowing down the game. TODO: delete the bullets when they're no longer relevant.
I've also made the folder with all the releases public, so anyone can look up the history without digging through the archives. Framework releases.
* It's fun for me, but then I had fun with the first release too.
So far, I've focused solely on functional details. Making models, making sure the models are displayed, movement, views and such. The result is... well, it's functional. Of course I want to have something good before I start polishing. A polished turd is still a turd, so I have to turn it into something else first.
The traditional way of making a background is making use of a skybox. This is basically a cube you draw around the scene. With the aid of something called cubemapping, you can slap the sky on the inside and the textures used fool the eye into thinking it's looking at a dome, rather than a cube. No seams or anything, if done correctly.
Of course, I didn't have the textures to make it look good handy.while there are plenty of images of space around, there's very few of a look at the complete sky, and those that are have fish eye effects. I could have slapped a few images, merged them together or something and called it a day, but I wanted something special.
So, I started a little side project. The idea being, I'd create the background out of a real galaxy I made up on the spot. This would mean create all the stars, jump into an appropriate position inside the galaxy and take pictures of what is visible in each direction. That way I would have the textures I needed for the cube map. I could scale the definition as much as I want, or move to a different spot and have the constelations in the background actually shift properly.
How to do it, though? A galaxy like our milky way has on the order of a hundred billion stars. Can't really draw them one at a time. Instead, my plan is to split the space the galaxy occupies into as many blocks as I can manage, and give it shape with the use of two functions.
One of the functions will give the galaxy a shape. The second will add some higher frequency noise to make it look more interesting.
I will represent the blocks with points, and once I have it all working try to improve the appearance. I really want the GPU to do the heavy lifting here. I can make a shader program that checks the position of each point and assigns it a value for each function, then multiplies them together. But if I tell the GPU to draw a million points one at a time, the overhead on the calls will slow things to a crawl. So what I do instead is make use of instanced drawing.
Instanced drawing means I tell the gpu to draw a singlemodel (in my case, as ingle point) as many times as I want. It's helpful for drawing many identical objects. The result, after setting the color to solid red, is not very impressive:
 |
| 4096 points, all drawn on top of each other. |
For my first test, I'm sending 0x1000 points to the gpu. That's 4096 in decimal, but you'll see why I work in hex in a bit. This means the instance ids range from 0x0 to 0xFFF (4095). What I can do is treat each of the hex digits as a coordinate in one of the axis, x, y and z, and move the point by that amount. So for example, the point 0x123 maps to position (1, 2, 3). I use bit masks and some bitwise arithmetic to work out the positions, which is why I do it this way. Computers, as you know, like binary and powers of 2 better than decimal.
Adding the instance id into the mix then, the result is a cube made of red dots. Not very impressinve right now, but it's a start.
 |
| I'm moving the points a bit, as well, so they appear centered. |

Ok, so back to the galaxy. First, I'll give it a proper shape. A cube is hardly the proper shape, so let's ignore points outside of a central sphere. For that, I'll give points further than 1 unit from the center a color of 0.1. There may be a few stragglers around the galaxy, but they're few and far between.

Much better. Now, galaxies tend to be shaped as disks, more than spheres, so we want to squash the sphere as well. What we want is to decrease the intensity with regards to the height from the plane. I'll use y to measure height from the plane, and to avoid the break being so obvious I'll also diminish the intensity along the diskthe farther you are from the center. The result:

Not so bad. Still need to add more features, though. For example, our galaxy has spiral arms. These will require a bit more thinking.
I didn't get quite as far as I meant to, mostly due to Deus Ex. Still, I don't want to leave you without an update so check out Framework-0.0.6r. You can do everything you could do before, and now shoot too! The space key now fires instead of accelerating, you accelerate with Left Shift. Fun* game to play: see how much you can shoot before it starts slowing down the game. TODO: delete the bullets when they're no longer relevant.
I've also made the folder with all the releases public, so anyone can look up the history without digging through the archives. Framework releases.
* It's fun for me, but then I had fun with the first release too.
Sunday, September 4, 2011
In the driver's seat
So I have a basic implementation of newtonian movement worked out. But we're still controlling an object that eventually flies off into the distance. And once it's out of view, it's pretty unlikely that it will come back. Wouldn't it be nice, though, if we could keep track of it?
Yes, yes it would. So having worked out movement, I focused on the camera. I decided to start with two views. One from the cockpit, which tracks the rotation of the object, and the other the familiar chase camera, looking at the object from behind, and tracking the direction of movement.
The reason I made these decisions is that movement in three dimensions is pretty unintuitive, specially when you remove friction. Most space flight games get around this unintuitiveness by treating space as a giant pool. You can remain buoyant at any spot, but there's a constant friction that slows you down as soon as you stop your engines. This allows people to point themselves in the direction they want to go and fire the engines. Any transversal motion will eventually be slowed enough that they end up reaching their destination with a minimum of effort.
With newtonian physics, however, there's no meaning to the idea of slowing down. Slowing down with respect to what? Speed is wholly relative. Firing your engines in the direction you want to go leads you to shoot around your target. It is madness. I needed a way to recover some of the intuitiveness, without sacrificing the fun of being in space.
The chase cam was my solution. Other games implement a chase view, but they waste it by keeping it aligned with the ship, so you're always watching your ship from behind. This is useful for shooting things, since weapons tend to be aligned with the front of the ship, but not so much for navigation. It's essentially the same as the cockpit view, only from outside the ship.
With my implementation, the player will see the direction they're actually moving in. If they want to head towards something, they have to align their objective with the center of this view. In the meantime, the ship is free to rotate any which way, and accelerating in different directions will shift the view. Ironically, racing games make a better use of the chase view than space flight games. For the most part you sit squarely behind the car, but you can notice when turning hard around corners or drifting that your car will turn while you keep looking in the direction that your car is still going in.
Still, shooting things is important. I can see how it would be quite distressing not to be able to see what you're shooting at, which is what the cockpit view is for. Eventually, helpful GUI elements will minimize the difficulty of getting from A to B when you don't have friction helping you along, but for a start the chase view should help.
Of course, before applying these views I had to populate the space somehow. A view from the cockpit in empty space would look completely static regardless of your movement. I decided to do two things. First, I draw a cube around the ship, which remains in a fixed orientation at all times. This let's you see how your orientation changes, but since you don't move around the cube but sit always in the middle, you can't see your translation. This is how skyboxes work, but since I don't have textures working yet green lines will have to do.
The second is, I actually start using all the infrastructure I'd been talking about before. During initialization I'm make a few different models (a sphere for 'asteroids', a piramid for the player), and store them in the cache. Then I create an entity for the player, and assign it the piramid model.
For the asteroids I do a little trick to get more variation. Based on the sphere model, I create new models which point to the same vertex buffers (where the sphere shape is stored in the video card), but add a scaling matrix to alter the size.
I make about fifty asteroids with random sizes and assign them random positions about the starting location for the player. Then during rendering I go through the list of entities, apply the scaling transformation and draw the result. Happily it works with very little additional fussing.
For the demo I only have the cockpit view working, which was pretty easy to implement by giving the camera the same reference frame as the player. It is available for download as usual: Framework-0.0.5r
Since it doesn't work on all machines just yet, I also created a short video of the demo.
So what's next? I should have the chase view working, and the possibility to switch between the two views. If I have the time I'll even throw in something special.
Yes, yes it would. So having worked out movement, I focused on the camera. I decided to start with two views. One from the cockpit, which tracks the rotation of the object, and the other the familiar chase camera, looking at the object from behind, and tracking the direction of movement.
The reason I made these decisions is that movement in three dimensions is pretty unintuitive, specially when you remove friction. Most space flight games get around this unintuitiveness by treating space as a giant pool. You can remain buoyant at any spot, but there's a constant friction that slows you down as soon as you stop your engines. This allows people to point themselves in the direction they want to go and fire the engines. Any transversal motion will eventually be slowed enough that they end up reaching their destination with a minimum of effort.
With newtonian physics, however, there's no meaning to the idea of slowing down. Slowing down with respect to what? Speed is wholly relative. Firing your engines in the direction you want to go leads you to shoot around your target. It is madness. I needed a way to recover some of the intuitiveness, without sacrificing the fun of being in space.
 |
| Surprisingly, still images do a poor job of demonstrating motion. |
With my implementation, the player will see the direction they're actually moving in. If they want to head towards something, they have to align their objective with the center of this view. In the meantime, the ship is free to rotate any which way, and accelerating in different directions will shift the view. Ironically, racing games make a better use of the chase view than space flight games. For the most part you sit squarely behind the car, but you can notice when turning hard around corners or drifting that your car will turn while you keep looking in the direction that your car is still going in.
Still, shooting things is important. I can see how it would be quite distressing not to be able to see what you're shooting at, which is what the cockpit view is for. Eventually, helpful GUI elements will minimize the difficulty of getting from A to B when you don't have friction helping you along, but for a start the chase view should help.
Of course, before applying these views I had to populate the space somehow. A view from the cockpit in empty space would look completely static regardless of your movement. I decided to do two things. First, I draw a cube around the ship, which remains in a fixed orientation at all times. This let's you see how your orientation changes, but since you don't move around the cube but sit always in the middle, you can't see your translation. This is how skyboxes work, but since I don't have textures working yet green lines will have to do.
 |
| So that's what those lines are for. |
For the asteroids I do a little trick to get more variation. Based on the sphere model, I create new models which point to the same vertex buffers (where the sphere shape is stored in the video card), but add a scaling matrix to alter the size.
I make about fifty asteroids with random sizes and assign them random positions about the starting location for the player. Then during rendering I go through the list of entities, apply the scaling transformation and draw the result. Happily it works with very little additional fussing.
For the demo I only have the cockpit view working, which was pretty easy to implement by giving the camera the same reference frame as the player. It is available for download as usual: Framework-0.0.5r
Since it doesn't work on all machines just yet, I also created a short video of the demo.
Saturday, September 3, 2011
Angular Momentum
A couple of posts back, when dealing with rotation, I wondered how I could model the property of angular momentum. Inertial momentum is easy enough to represent with a speed vector which you add to the entity's position every frame. Velocity shares several characteristics with rotation, surprisingly. In physics angular velocity is also represented with a vector, with the direction determining the axis of rotation and the length the angular speed. I figured this was, after all, everything I needed. It would make sense then to try to use it.
It wasn't too much work to add a vector to the entity object, and modify the code so that pressing the rotation keys would add to this vector. The rather clever bit, I think, is that I store the vector in world coordinates. By keeping track of the frame of reference for my objects I can easily convert between local and world coordinates. This is important because I add rotation along the three local axis, but convert the addition to global coordinates before adding them to my rotation vector.
Then in the update logic I rotate along the vector's axis by an amount determined by its length. One thing to keep in mind though is that to make the rotation look realistic, I have to center models on their center of mass. Easy enough on regular geometric shapes, but I'll have to figure out something for complex models, or models with moving parts.
The demo for this is available for download: Framework-0.0.4r
It's fun to mess around with. There's a weird effect that happens when you spin up significantly, and the refresh rate starts to match up with the turning speed and the sphere appears to slow down or rotate backwards.
You can also hopelessly lose control of the thing if you mix too much spin in different directions. It should be possible to recover from the perspective of someone inside, since you can easily break down the spin one axis at a time. That's something for the next update, though.
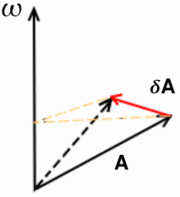 |
| The farther away from the axis of rotation, the greater the change in position. |
Then in the update logic I rotate along the vector's axis by an amount determined by its length. One thing to keep in mind though is that to make the rotation look realistic, I have to center models on their center of mass. Easy enough on regular geometric shapes, but I'll have to figure out something for complex models, or models with moving parts.
The demo for this is available for download: Framework-0.0.4r
It's fun to mess around with. There's a weird effect that happens when you spin up significantly, and the refresh rate starts to match up with the turning speed and the sphere appears to slow down or rotate backwards.
You can also hopelessly lose control of the thing if you mix too much spin in different directions. It should be possible to recover from the perspective of someone inside, since you can easily break down the spin one axis at a time. That's something for the next update, though.
Thursday, September 1, 2011
Modeling a sphere, the new way
Back when I began this blog, almost a year ago, I set a goal for myself of drawing a sphere. Back then I didn't know about the fixed pipeline, and how it had been replaced by shaders and a more flexible approach. I was pretty much learning as I went, and I was just starting out.
Now on my 50th post, I have a bit more experience under my belt, and it's interesting to see how far I've come and how I've changed the approach for doing exactly the same. It hasn't been easy or smooth, I've had to start over three or four times, but through it all I've progressed.
Last year my approach had used the fixed pipeline, and I was sending triangle strips to be rendered, one slice of the sphere at a time. This time, what I've done is create a set of vertices, and build the triangles by connecting the dots. By creating a vertex buffer array, the information is stored in the video memory meaning I don't have to send a load of data to the graphics card each frame.
Fair warning, there's a bit of geometry ahead. I'll try to be clear.
I want to find the positions of the points at the intersections, which are the ones I'll use as vertices for my triangles. My approach is to loop through the grid, finding the spherical coordinates (radius, angle theta from the horizontal plane and angle phi around the axis) for each point and translating them to Cartesian coordinates (x, y, z).
To make matters easier I'll create a sphere with radius 1. If I want to use a larger sphere later, I can just scale the model accordingly. I'm also going to be working out the normals for each point. Since this is a sphere with radius 1, though, the normals will be the same as the coordinates.
Working out the spherical coordinates of the points is simple enough. Theta can vary between 0 and pi, and phi can vary between 0 and 2*pi. For a sphere of a given resolution, determined by the number of cuts and slices I use, I can determine the variation between grid points along each coordinate. With three cuts for example, the theta values would be 0 (for the north pole), pi/4 (45°), pi/2(90°, ecuator), 3pi/4 (135°) and pi (for the south pole).
Then it's just a matter of looping through all the possible values for each spherical coordinate, and translating to Cartesian, which is a simple trigonometry operation.
I now have a list with all the points in the sphere. The next thing I need to do is to create a list of indices, telling me which points make each triangle. If I had the four points
I could use the two triangles define by the points 1,2,4 and 2,3,4 to build a square, for example. With the sphere it's the same. Knowing how I traverse the sphere in the first place, I can determine which points build the triangles on the surface. It's important though to consider that the polar caps of the model behave differently than the main body, but that special case is simple enough to handle.
After I've stored all this information in arrays, I need to feed it to the video card. I build a vertex buffer array, which stores information about what buffer objects to use, and several vertex buffer objects to actually store the information. For each point I'm storing it's position, normal, color, and texture coordinates. Add the index array for telling the card how to group them into triangles, and I need to use five buffers. On the plus side, that's a whole lot of information I no longer need to worry about. When I next wish to draw the sphere, I simply bind the vertex buffer array and draw it.
The result is visible in the demo for Framewrok-0.0.3r, where I changed the old single triangle model for a fairly detailed sphere.
Now on my 50th post, I have a bit more experience under my belt, and it's interesting to see how far I've come and how I've changed the approach for doing exactly the same. It hasn't been easy or smooth, I've had to start over three or four times, but through it all I've progressed.
Last year my approach had used the fixed pipeline, and I was sending triangle strips to be rendered, one slice of the sphere at a time. This time, what I've done is create a set of vertices, and build the triangles by connecting the dots. By creating a vertex buffer array, the information is stored in the video memory meaning I don't have to send a load of data to the graphics card each frame.
Same as before, I'm cutting the sphere like a globe, with parallels running east to west and meridians running north to south.
 |
| In spherical coordinates, parallels correspond to theta values and meridians to phi values. |
I want to find the positions of the points at the intersections, which are the ones I'll use as vertices for my triangles. My approach is to loop through the grid, finding the spherical coordinates (radius, angle theta from the horizontal plane and angle phi around the axis) for each point and translating them to Cartesian coordinates (x, y, z).
To make matters easier I'll create a sphere with radius 1. If I want to use a larger sphere later, I can just scale the model accordingly. I'm also going to be working out the normals for each point. Since this is a sphere with radius 1, though, the normals will be the same as the coordinates.
Working out the spherical coordinates of the points is simple enough. Theta can vary between 0 and pi, and phi can vary between 0 and 2*pi. For a sphere of a given resolution, determined by the number of cuts and slices I use, I can determine the variation between grid points along each coordinate. With three cuts for example, the theta values would be 0 (for the north pole), pi/4 (45°), pi/2(90°, ecuator), 3pi/4 (135°) and pi (for the south pole).
Then it's just a matter of looping through all the possible values for each spherical coordinate, and translating to Cartesian, which is a simple trigonometry operation.
I now have a list with all the points in the sphere. The next thing I need to do is to create a list of indices, telling me which points make each triangle. If I had the four points
1 ( 0, 1, 0)
2 (-1, 0, 0)
3 ( 0,-1, 0)
4 ( 1, 0, 0)
I could use the two triangles define by the points 1,2,4 and 2,3,4 to build a square, for example. With the sphere it's the same. Knowing how I traverse the sphere in the first place, I can determine which points build the triangles on the surface. It's important though to consider that the polar caps of the model behave differently than the main body, but that special case is simple enough to handle.
After I've stored all this information in arrays, I need to feed it to the video card. I build a vertex buffer array, which stores information about what buffer objects to use, and several vertex buffer objects to actually store the information. For each point I'm storing it's position, normal, color, and texture coordinates. Add the index array for telling the card how to group them into triangles, and I need to use five buffers. On the plus side, that's a whole lot of information I no longer need to worry about. When I next wish to draw the sphere, I simply bind the vertex buffer array and draw it.
The result is visible in the demo for Framewrok-0.0.3r, where I changed the old single triangle model for a fairly detailed sphere.
Wednesday, August 31, 2011
Rotation
With translation out of the way, I moved on to something more complicated. Rotation.
The last time I went about it, I tried it with quaternions. It was time consuming and I'm not entirely sure how it even ended up working. Euler angles are even worse. Vectors and matrices, however, seem more suited to solve the problem and play nice with OpenGL. And since the GLTools library I'm using already handles that, I really only need to wrap a few calls in my entities to get it working.
As I mentioned in my previous post, I have a reference frame determined by three vectors and a position. This makes local rotations simple. If I want to roll along the length of the model, I rotate around the forward vector. If I want to change the pitch of the model, I rotate around the right vector. And if I want to turn to either side, I rotate around the up vector.
I do the same basic set up as I did for translation, except my keys now affect rotation. I tie each pair of keys to a fixed rotation around each of my local axis, so that as long as I hold a key the model rotates and on release it stops rotating.
This gets the model turning about, and to spice things up I decide to give it the ability to accelerate. I first create a velocity vector, initially set to 0 so the body is at rest. Then, when I accelerate, I add to the vector a speed increment in the forward direction. When it comes time to update my entity's position, I add the velocity vector to it's position and done. This models newtonian movement well enough; velocity is constant unless I accelerate in a given direction. If I want to stop, I have to accelerate in the opposite direction to my movement.
I can rotate around independently of my direction of movement because I store the velocity vector in global coordinates. I could easily work out the vector in local coordinates as well, and it would provide a vector that moves around as I rotate the ship.
The result is Framework-0.0.2r.
What is missing, however, is that rotation should also be continuous unless I stop it. I'm modeling conservation of momentum, but not of angular momentum. I would need to store another vector, much like the velocity vector, which is affected by what kind of rotation I attempt. Unfortunately I'm not 100% sure on the physics involved here. Ideally I could just add vectors, same as with speed. The angle of rotation would be determined by the magnitude of the vector, while the axis of rotation would be the direction of the vector. That feels about right, and I should have it set up for Framework-0.0.4r.
Next up, I reworked my sphere building algorithms from the very beginnings of this blog. I used to use triangle strips, but together with the fixed pipeline that's obsolete. Vertex lists and indices is where it's at now.
The last time I went about it, I tried it with quaternions. It was time consuming and I'm not entirely sure how it even ended up working. Euler angles are even worse. Vectors and matrices, however, seem more suited to solve the problem and play nice with OpenGL. And since the GLTools library I'm using already handles that, I really only need to wrap a few calls in my entities to get it working.
As I mentioned in my previous post, I have a reference frame determined by three vectors and a position. This makes local rotations simple. If I want to roll along the length of the model, I rotate around the forward vector. If I want to change the pitch of the model, I rotate around the right vector. And if I want to turn to either side, I rotate around the up vector.
I do the same basic set up as I did for translation, except my keys now affect rotation. I tie each pair of keys to a fixed rotation around each of my local axis, so that as long as I hold a key the model rotates and on release it stops rotating.
This gets the model turning about, and to spice things up I decide to give it the ability to accelerate. I first create a velocity vector, initially set to 0 so the body is at rest. Then, when I accelerate, I add to the vector a speed increment in the forward direction. When it comes time to update my entity's position, I add the velocity vector to it's position and done. This models newtonian movement well enough; velocity is constant unless I accelerate in a given direction. If I want to stop, I have to accelerate in the opposite direction to my movement.
I can rotate around independently of my direction of movement because I store the velocity vector in global coordinates. I could easily work out the vector in local coordinates as well, and it would provide a vector that moves around as I rotate the ship.
The result is Framework-0.0.2r.
What is missing, however, is that rotation should also be continuous unless I stop it. I'm modeling conservation of momentum, but not of angular momentum. I would need to store another vector, much like the velocity vector, which is affected by what kind of rotation I attempt. Unfortunately I'm not 100% sure on the physics involved here. Ideally I could just add vectors, same as with speed. The angle of rotation would be determined by the magnitude of the vector, while the axis of rotation would be the direction of the vector. That feels about right, and I should have it set up for Framework-0.0.4r.
Next up, I reworked my sphere building algorithms from the very beginnings of this blog. I used to use triangle strips, but together with the fixed pipeline that's obsolete. Vertex lists and indices is where it's at now.
Progress!
Lots to talk about. I haven't been posting here as often as I'd like, but I have managed to get quite a bit of work done.
Let's see, last time, I had a triangle on the screen. And I wanted to make it interactive. The first thing I did was create a few methods in my entity object that would modify the entity's frame of reference.The frame of reference describes the position and orientation of something in space, and helps translate between local and global coordinates.
Local coordinates are coordinates from the object's point of view, while global coordinates are the coordinate system of the world the object is in. For ease of reading, I'll denote local coordinates as (x,y,z)l, and global coordinates as (x,y,z)g.
From the object's perspective (meaning in local coordinates), all points are static. It's center is always at (0,0,0)l, and the axis are always (1,0,0)l,(0,1,0)l and (0,0,1)l. A point at (1,1,1)l is always at (1,1,1)l.
The same point in global coordinates, however, depends on the position and orientation of the object in the world. When the object sits still at the global origin, both coordinate systems match up. If the object moves 1 unit forward, so the local origin now sits at (1,0,0)g, then the point that is (1,1,1)l is actually (2,1,1)g.
We can define a frame of reference as an origin (the position in global coordinates), a forward vector (in global coordinates) and an up vector (in global coordinates). From the cross product of these two vectors I can get the right vector, and these three determine the orientation of the local coordinate axis.
That's the difficult part out of the way, then.
I started with translation, which was easy enough. In order to advance 'forwards', I need to advance along the object's forward vector. To do this, I simply add the forward vector times a speed factor to the object's origin, and tie this to a key input. I can do the same with the up and right vectors, and the result is that the object will move around the screen when you press a key.
Quite surprisingly, I did it, and it worked! I was on a roll, so I even modified the shader so it would accept the color of a given point and shade the resulting triangle with the value of each point.
I'll put up a few screenshots later. I'm also thinking I'll put the demo here just in case. If I can work out how to do it.
And I did, thanks to google. Now you too can get Framework 0.0.1r! You only need 7zip to uncompress it, and it comes ready to run.
Let's see, last time, I had a triangle on the screen. And I wanted to make it interactive. The first thing I did was create a few methods in my entity object that would modify the entity's frame of reference.The frame of reference describes the position and orientation of something in space, and helps translate between local and global coordinates.
Local coordinates are coordinates from the object's point of view, while global coordinates are the coordinate system of the world the object is in. For ease of reading, I'll denote local coordinates as (x,y,z)l, and global coordinates as (x,y,z)g.
From the object's perspective (meaning in local coordinates), all points are static. It's center is always at (0,0,0)l, and the axis are always (1,0,0)l,(0,1,0)l and (0,0,1)l. A point at (1,1,1)l is always at (1,1,1)l.
The same point in global coordinates, however, depends on the position and orientation of the object in the world. When the object sits still at the global origin, both coordinate systems match up. If the object moves 1 unit forward, so the local origin now sits at (1,0,0)g, then the point that is (1,1,1)l is actually (2,1,1)g.
We can define a frame of reference as an origin (the position in global coordinates), a forward vector (in global coordinates) and an up vector (in global coordinates). From the cross product of these two vectors I can get the right vector, and these three determine the orientation of the local coordinate axis.
That's the difficult part out of the way, then.
I started with translation, which was easy enough. In order to advance 'forwards', I need to advance along the object's forward vector. To do this, I simply add the forward vector times a speed factor to the object's origin, and tie this to a key input. I can do the same with the up and right vectors, and the result is that the object will move around the screen when you press a key.
Quite surprisingly, I did it, and it worked! I was on a roll, so I even modified the shader so it would accept the color of a given point and shade the resulting triangle with the value of each point.
I'll put up a few screenshots later. I'm also thinking I'll put the demo here just in case. If I can work out how to do it.
And I did, thanks to google. Now you too can get Framework 0.0.1r! You only need 7zip to uncompress it, and it comes ready to run.
Monday, August 8, 2011
Back to square one again!
Well, I spent a lot of time scratching my head over a problem that turned out to be a simple dumb issue.
As I detailed in my last post, my models consists of pointers to video memory where the actual information is stored. In a fit of genius, I realized that if I deleted the model but forgot to clean up the information, I'd be leaking video memory. That would be bad. So I made sure that, before a model is destroyed, the information is cleaned up.
This seemed like a clever solution, and the subtle problem didn't become obvious to me until I spent two weeks wondering what I was doing wrong.
The problem happened with copying the model. I created the model in one part of the program, and copied it to the cache that would store it. This preserved the pointers, but when the original model was cleaned up it cleaned up the video memory. Just as I told it to. The copy was then left with pointers that were no longer valid. So when I then asked the program to render the model, it couldn't.
Thankfully the problem wasn't hard to solve. I instead created the model in a space in memory where I have more control of when it gets destroyed, and copy instead a pointer to it. This way the model object itself is never copied or destroyed and I can store it directly. In the process I learned a bit, so I call it a success.
I also had to add a shader to the program, which I should have probably worked into the framework before I did the work on the models. Thankfully I had a ready made function that handles all the aspects of reading the shader from file, loading it to video memory, compiling, linking and binding attributes.
So now, after a couple of months, I'm able to render a red triangle to the screen. Which is about what I was at before the rewrite. So, yay?
Well, to be honest I have a lot more than before. I can read input, and configure it (just need to add more input to be read). My storage is a lot more organized and extensible. I need to do some adjustments to my design to account for lessons learned, but I'm very happy with what I have.
Next up, I'll be adding some actual interactivity. Well, first deal with matrices, then interactivity.
As I detailed in my last post, my models consists of pointers to video memory where the actual information is stored. In a fit of genius, I realized that if I deleted the model but forgot to clean up the information, I'd be leaking video memory. That would be bad. So I made sure that, before a model is destroyed, the information is cleaned up.
This seemed like a clever solution, and the subtle problem didn't become obvious to me until I spent two weeks wondering what I was doing wrong.
The problem happened with copying the model. I created the model in one part of the program, and copied it to the cache that would store it. This preserved the pointers, but when the original model was cleaned up it cleaned up the video memory. Just as I told it to. The copy was then left with pointers that were no longer valid. So when I then asked the program to render the model, it couldn't.
Thankfully the problem wasn't hard to solve. I instead created the model in a space in memory where I have more control of when it gets destroyed, and copy instead a pointer to it. This way the model object itself is never copied or destroyed and I can store it directly. In the process I learned a bit, so I call it a success.
I also had to add a shader to the program, which I should have probably worked into the framework before I did the work on the models. Thankfully I had a ready made function that handles all the aspects of reading the shader from file, loading it to video memory, compiling, linking and binding attributes.
So now, after a couple of months, I'm able to render a red triangle to the screen. Which is about what I was at before the rewrite. So, yay?
Well, to be honest I have a lot more than before. I can read input, and configure it (just need to add more input to be read). My storage is a lot more organized and extensible. I need to do some adjustments to my design to account for lessons learned, but I'm very happy with what I have.
Next up, I'll be adding some actual interactivity. Well, first deal with matrices, then interactivity.
Tuesday, July 12, 2011
Top Models
With everything I've done, it's about time I start getting to drawing something to the screen. Before I can do that, however, I have to define what it is I'm going to draw. The shapes that describe the different objects in the world are called models.
Models in three dimensions are composed of triangles, and these are made up of three vertices each. A vertex (singular of vertices) is described by several numbers. We need it's position in space, which is described by three coordinates (x,y,z). We also need the normal for each point, which is used in lighting calculations and describes a direction perpendicular to the surface. This vector is also described by three values and should be of unit length. We can specify a color for each point, which requires the color values (RGB, greyscale, transparency, etc). Finally we have the texture coordinates, which describe the point on a texture that should be mapped to the vertex. Since textures are flat, this is accomplished with just two values, (u,v).
This means there are between nine and twelve values that describe a point. These values can be stored on the video card itself, using structures called Vertex Buffer Objects. Each of these objects can be called with a unique ID called names, which OpenGL provides when you request the creation of one.
This means that my model structure in the program needs to know only the VBO name.
When storing the vertex positions, however, I am doing it in the model coordinates. Depending on how I translate them to screen coordinates, I could scale or stretch the model. If I want to draw a large sphere and a small sphere, I could either store the points for each, or I could store the points for a unit sphere and scale it to the size I want.
Additionally, I could have a model consisting of different sub-models. For example, one could create a snowman out of reusing the model for a sphere, instead of a single model storing the values of two spheres. In order to do this, the snowman model would need the name of the basic sphere and two matrices, to scale and translate the spheres to the correct shape and position.
This implies two kinds of models. The primitives would consist of the Vertex Buffer Object names, while the complex ones would consist of a list of primitives and matrices applied to them. Of course, the list could also contain other complex models itself. These two types could be condensed if we stored both properties in every model. Primitive types would hold empty lists, while the VBO names for complex types would be null.
The models would then be stored in the model cache, and different entities would call them when needed.
I would still need methods for loading the vertex information into the buffers, however, and for drawing them. But this is something to look into in another post.
Models in three dimensions are composed of triangles, and these are made up of three vertices each. A vertex (singular of vertices) is described by several numbers. We need it's position in space, which is described by three coordinates (x,y,z). We also need the normal for each point, which is used in lighting calculations and describes a direction perpendicular to the surface. This vector is also described by three values and should be of unit length. We can specify a color for each point, which requires the color values (RGB, greyscale, transparency, etc). Finally we have the texture coordinates, which describe the point on a texture that should be mapped to the vertex. Since textures are flat, this is accomplished with just two values, (u,v).
This means there are between nine and twelve values that describe a point. These values can be stored on the video card itself, using structures called Vertex Buffer Objects. Each of these objects can be called with a unique ID called names, which OpenGL provides when you request the creation of one.
This means that my model structure in the program needs to know only the VBO name.
When storing the vertex positions, however, I am doing it in the model coordinates. Depending on how I translate them to screen coordinates, I could scale or stretch the model. If I want to draw a large sphere and a small sphere, I could either store the points for each, or I could store the points for a unit sphere and scale it to the size I want.
Additionally, I could have a model consisting of different sub-models. For example, one could create a snowman out of reusing the model for a sphere, instead of a single model storing the values of two spheres. In order to do this, the snowman model would need the name of the basic sphere and two matrices, to scale and translate the spheres to the correct shape and position.
This implies two kinds of models. The primitives would consist of the Vertex Buffer Object names, while the complex ones would consist of a list of primitives and matrices applied to them. Of course, the list could also contain other complex models itself. These two types could be condensed if we stored both properties in every model. Primitive types would hold empty lists, while the VBO names for complex types would be null.
The models would then be stored in the model cache, and different entities would call them when needed.
I would still need methods for loading the vertex information into the buffers, however, and for drawing them. But this is something to look into in another post.
Saturday, July 9, 2011
Event handling done, and a bit about File I/O
Well, the bare-bones version of the event handling system is done. There are some improvements to make, and I only support a few keys and commands still, but the system is fairly robust and extensible. Plus, the key mappings are read from configuration files now, so they can be modified without recompiling.
The shape it has taken, in the end, is quite close to my original design. I created an Event Interpreter, which receives the system events and returns a command. In order to do this, it has a list of contexts where it searches for the event. Each context consists of a map, using events as the key.
The order of contexts is important, since an event can have different meanings in each. The contexts closer to the top have priority, however, and they override the commands in lower contexts. During the course of the program, the contexts may shift up and down, or even be removed completely and held in a holding stack in order to disable a set of commands at once.
In order to load the contexts in the begining, the program reads a text configuration file. The file is structured such that contexts are marked by curly braces ({}), and are composed of lines delimited by semi colons (;). Each line consists of an Event:Command pair, separated by a colon (:). The properties of each event and command, which identify them, are set apart by commas. So a simplex context would look like
I'll probably end up adding an identifier for the Context. As it stands, I can comment anywhere between Contexts, but I have to be careful about what I write inside them. I should add a validation code of some kind. A missing file can hang the program right now.
I'm pretty happy about how the file reading code came out. String manipulation in C++ isn't trivial, whic is one of the reasons why everyone usually ends up rolling their own string class. I managed to deal with it fairly cleanly, though. I can't handle encodings other than ANSI (maybe UTF-8, haven't tested), but for a configuration file this shouldn't be a problem.
Now that this is done, however, I need to consider what else needs to be done. I think it's about time I gave the drawing code another look. I can work on other parts, but for testing purposes being able to see the effect of things in the screen would be a lot more useful. I'm hoping to be able to create assets in real time, which is one of the main drives in the project, and I need to be able to see the output ahead of everything else.
This means giving the resource caches another look as well. So I'll be having some fun.
The shape it has taken, in the end, is quite close to my original design. I created an Event Interpreter, which receives the system events and returns a command. In order to do this, it has a list of contexts where it searches for the event. Each context consists of a map, using events as the key.
The order of contexts is important, since an event can have different meanings in each. The contexts closer to the top have priority, however, and they override the commands in lower contexts. During the course of the program, the contexts may shift up and down, or even be removed completely and held in a holding stack in order to disable a set of commands at once.
In order to load the contexts in the begining, the program reads a text configuration file. The file is structured such that contexts are marked by curly braces ({}), and are composed of lines delimited by semi colons (;). Each line consists of an Event:Command pair, separated by a colon (:). The properties of each event and command, which identify them, are set apart by commas. So a simplex context would look like
{EventType, EventCode, : CommandType, CommandCode,;}
I'll probably end up adding an identifier for the Context. As it stands, I can comment anywhere between Contexts, but I have to be careful about what I write inside them. I should add a validation code of some kind. A missing file can hang the program right now.
I'm pretty happy about how the file reading code came out. String manipulation in C++ isn't trivial, whic is one of the reasons why everyone usually ends up rolling their own string class. I managed to deal with it fairly cleanly, though. I can't handle encodings other than ANSI (maybe UTF-8, haven't tested), but for a configuration file this shouldn't be a problem.
Now that this is done, however, I need to consider what else needs to be done. I think it's about time I gave the drawing code another look. I can work on other parts, but for testing purposes being able to see the effect of things in the screen would be a lot more useful. I'm hoping to be able to create assets in real time, which is one of the main drives in the project, and I need to be able to see the output ahead of everything else.
This means giving the resource caches another look as well. So I'll be having some fun.
Monday, July 4, 2011
Event Handling
So back to the matter of Events. These represent the interactions the player can have with the program. On the one hand, you have everything the player can do with the computer; pressing keys, moving the mouse, etc. On the other, you have the actions you can assign to one or more of these keys; moving the character, using items, shooting, etc.
The SFML already provides me with the player events. What I have to do is create the actions that correspond to them. I would then have a function that is fed an event and outputs the correct action. I'll start with the most basic event: a command to close the window and end the execution of the program. I'll provide the 'Esc' button for it.
After reading the events and generating the associated commands, I have to execute the command. For the most part, these commands are going to represent state changes in the game, and not so much actions themselves. In the case of a move forward command, pressing the 'move forward' key would toggle the entity's state to 'is moving forward', and releasing it would reset it to 'is stopped'. Then in the update loop the game would check if the player 'is moving forward' and if so advance it's position.
Of course, if I have each command execute itself from the event loop, I have to riddle the entity interface, and anything the player can interact with, with functions to access the members that define their state. Instead what I'll do is read the command, build a command queue for each target that might receive a command, and pass the stack to the target. That way the target (be it an entity, the window or whatever) can apply the commands internally.
I'll start with some basic commands: 'Esc' to close the game, and 'WASD' to move forward and back and strafe left and right. I'll use 'Esc' on press, meaning as soon as the key is pressed the program will end. The four keys will actually mean eight commands. Four to start and four to stop, on press and on release respectively. This allows to have several keys pressed at once, and if opposite keys are pressed, they can both be applied (it would result in no effect at all, but it wouldn't bother the game).
My command class is going to mirror the structure of the event class provided by SFML. It will consist of an enumeration describing the kind of command it is, such as a window or movement command, and a union of structs that each describe the kind of command in detail.
The Commands are mapped to Events in structures called Contexts. Each context represents a set of Commands that are available. We do this because particular keys could have different meanings depending on the state of the game. For example, it could be that when the inventory is open, the movement commands are disabled. The contexts give the ability to remap keys and alter the available commands on the fly.
Well, this gives a bit of an overview of how I'll be handling user input. Next up, I'll be describing the process in more detail as I finish writing it up. I have the basic structures coded now, but I still need to assemble it all together.
The SFML already provides me with the player events. What I have to do is create the actions that correspond to them. I would then have a function that is fed an event and outputs the correct action. I'll start with the most basic event: a command to close the window and end the execution of the program. I'll provide the 'Esc' button for it.
After reading the events and generating the associated commands, I have to execute the command. For the most part, these commands are going to represent state changes in the game, and not so much actions themselves. In the case of a move forward command, pressing the 'move forward' key would toggle the entity's state to 'is moving forward', and releasing it would reset it to 'is stopped'. Then in the update loop the game would check if the player 'is moving forward' and if so advance it's position.
Of course, if I have each command execute itself from the event loop, I have to riddle the entity interface, and anything the player can interact with, with functions to access the members that define their state. Instead what I'll do is read the command, build a command queue for each target that might receive a command, and pass the stack to the target. That way the target (be it an entity, the window or whatever) can apply the commands internally.
I'll start with some basic commands: 'Esc' to close the game, and 'WASD' to move forward and back and strafe left and right. I'll use 'Esc' on press, meaning as soon as the key is pressed the program will end. The four keys will actually mean eight commands. Four to start and four to stop, on press and on release respectively. This allows to have several keys pressed at once, and if opposite keys are pressed, they can both be applied (it would result in no effect at all, but it wouldn't bother the game).
My command class is going to mirror the structure of the event class provided by SFML. It will consist of an enumeration describing the kind of command it is, such as a window or movement command, and a union of structs that each describe the kind of command in detail.
The Commands are mapped to Events in structures called Contexts. Each context represents a set of Commands that are available. We do this because particular keys could have different meanings depending on the state of the game. For example, it could be that when the inventory is open, the movement commands are disabled. The contexts give the ability to remap keys and alter the available commands on the fly.
Well, this gives a bit of an overview of how I'll be handling user input. Next up, I'll be describing the process in more detail as I finish writing it up. I have the basic structures coded now, but I still need to assemble it all together.
Saturday, July 2, 2011
Crappy week
Caught a cold during the weekend, and I just couldn't get anything done during the week. A few late nights didn't help, either. So, I managed to look at event handling a bit, got some promising ideas, but that's not what I'll be working on just now.
I am going to, instead, work a little more on the resources, wrap that up for now, then move on. I had a few interesting thoughts before, and then someone pointed out that keeping a pointer and a count of times it's been referenced is a lot like having a smart pointer. Boost offers a number of them, of which 'shared_ptr' seemed to be the most appropriate. The way they work is that, so long as I refrain from using regular pointers, I should not have dangling pointers (pointers aimed at a resource I already freed) because the pointers share a counter themselves. Only once all references to a memory address have been lost is the memory freed.
So what I'll do is, when reading a file, create a resource and point to it with a shared pointer. I then store the shared pointer in a map, and key it to a string value (for now, just the name of the file). Then I can have anyone who needs it get a copy of the shared pointer, and keep track of how many people hold pointers to each value. Then instead of using handles to get a pointer (which I didn't do to avoid the problems with naked pointers in the first place), I can use the smart pointer itself.
For now I'll give the cache limited functionality. It can load a pointer, given a string to key it with, and it can produce the pointer, given the key. The other cool thing about smart pointers is that I don't need to worry so much about erasing things just yet. Not only do they not erase the resource until it's not needed by the last reference, but when the last reference to it dies one way or another, it is deleted automatically as well. So no memory leaks. Of course, since the cache holds a reference, the resources won't be freed unless I specifically say so.
The matter of reading a file is still something I'm struggling with. There are several ways of going about it. I'll do the more flexible one for now, and consider how to refactor the code later. What I'll be doing is storing all the code for turning files into resources in one class, the caches to store the resources as another class, and the code to call them in the framework class that holds them both.
There, back in business. And hey, these changes don't even require that I change (too much) my previous code! The file reading code just needs to be updated to provide shared pointers instead of naked pointers. So I should be able to test that the changes don't break anything easily enough.
Anyway, it's been too long without any pretty drawings, so I'm going to be delving into some stuff way off in the future in the next few posts, while I silently toil at the boring backbone stuff.
I am going to, instead, work a little more on the resources, wrap that up for now, then move on. I had a few interesting thoughts before, and then someone pointed out that keeping a pointer and a count of times it's been referenced is a lot like having a smart pointer. Boost offers a number of them, of which 'shared_ptr' seemed to be the most appropriate. The way they work is that, so long as I refrain from using regular pointers, I should not have dangling pointers (pointers aimed at a resource I already freed) because the pointers share a counter themselves. Only once all references to a memory address have been lost is the memory freed.
So what I'll do is, when reading a file, create a resource and point to it with a shared pointer. I then store the shared pointer in a map, and key it to a string value (for now, just the name of the file). Then I can have anyone who needs it get a copy of the shared pointer, and keep track of how many people hold pointers to each value. Then instead of using handles to get a pointer (which I didn't do to avoid the problems with naked pointers in the first place), I can use the smart pointer itself.
For now I'll give the cache limited functionality. It can load a pointer, given a string to key it with, and it can produce the pointer, given the key. The other cool thing about smart pointers is that I don't need to worry so much about erasing things just yet. Not only do they not erase the resource until it's not needed by the last reference, but when the last reference to it dies one way or another, it is deleted automatically as well. So no memory leaks. Of course, since the cache holds a reference, the resources won't be freed unless I specifically say so.
The matter of reading a file is still something I'm struggling with. There are several ways of going about it. I'll do the more flexible one for now, and consider how to refactor the code later. What I'll be doing is storing all the code for turning files into resources in one class, the caches to store the resources as another class, and the code to call them in the framework class that holds them both.
There, back in business. And hey, these changes don't even require that I change (too much) my previous code! The file reading code just needs to be updated to provide shared pointers instead of naked pointers. So I should be able to test that the changes don't break anything easily enough.
Anyway, it's been too long without any pretty drawings, so I'm going to be delving into some stuff way off in the future in the next few posts, while I silently toil at the boring backbone stuff.
Sunday, June 26, 2011
Managing Resources
I have made some progress in managing resources. I'm almost up to the point where I need to start thinking about incorporating drawing code to see the progress, but I'm resisting the temptation. Once I have that up, it's going to take too much attention away from drawing the basic infrastructure.
Instead, I'm looking into how to manage my resources. There are three basic things you need to do with resources (be they models, entities, sounds or whatever). They need to be loaded from files (or created procedurally), they need to be called during play, and they have to be unloaded when not needed any more. My current problem is with all three.
I'm trying to determine what the best way to handle them in each situation is. Before calling up a specific file to load, I need to know what specific resource I need, and check if it is already loaded. If it isn't, then I look up the file and load it. Consider the case of models, for example. Several entities might use the same model. There's no point in storing in the entity the filename of the model, since then I'd be loading the model once per entity. I'd need a table of some kind that looks up a specific filename and checks to see if it is loaded or not. If it is loaded, it would provide the 'model id' that the system assigned it when loading it, and that can be used to refer to it. Otherwise it loads the file, assigns it a model id, and then returns it.
Hmm, that could work, I guess.
I already implemented a way to ensure that the vector holding the pointers to the resources doesn't fill up with holes at least. I'll keep a count of how many pointers are stored in it, which increases when added to and decreses when one is freed. Then I can know if any holes develop by comparing the size of the vector to the number of resources loaded. If when loading a new resource I find that there's a hole, I'll search the vector for the hole and use the first I come upon.
So coming up, more design work. I'm kinda sorta stuck in that I don't know where exactly to move forward. All of the code needs to be worked on. I'll spend the next week looking at the event handling, that should provide some interesting avenues to make inroads.
Instead, I'm looking into how to manage my resources. There are three basic things you need to do with resources (be they models, entities, sounds or whatever). They need to be loaded from files (or created procedurally), they need to be called during play, and they have to be unloaded when not needed any more. My current problem is with all three.
I'm trying to determine what the best way to handle them in each situation is. Before calling up a specific file to load, I need to know what specific resource I need, and check if it is already loaded. If it isn't, then I look up the file and load it. Consider the case of models, for example. Several entities might use the same model. There's no point in storing in the entity the filename of the model, since then I'd be loading the model once per entity. I'd need a table of some kind that looks up a specific filename and checks to see if it is loaded or not. If it is loaded, it would provide the 'model id' that the system assigned it when loading it, and that can be used to refer to it. Otherwise it loads the file, assigns it a model id, and then returns it.
Hmm, that could work, I guess.
I already implemented a way to ensure that the vector holding the pointers to the resources doesn't fill up with holes at least. I'll keep a count of how many pointers are stored in it, which increases when added to and decreses when one is freed. Then I can know if any holes develop by comparing the size of the vector to the number of resources loaded. If when loading a new resource I find that there's a hole, I'll search the vector for the hole and use the first I come upon.
So coming up, more design work. I'm kinda sorta stuck in that I don't know where exactly to move forward. All of the code needs to be worked on. I'll spend the next week looking at the event handling, that should provide some interesting avenues to make inroads.
Friday, June 24, 2011
Main loop
I've been working on the infrastructure for the program. Matters like resource handling, memory structure and access to functionality. These are important, but don't describe the program itself. I can have test runs with programs that try the functionality of different aspects of the program, but they're not what I'm after.
Games have a pretty standard structure. They're basically a loop, where you poll for input, update the state, and render to the screen. This loop runs dozens of times per second in a normal game. A game running at thirty fps is running through this loop thirty times per second. Each run is generally referred to as a frame, since you can consider the discrete changes in state between each run a snapshot, and the sequence of snapshots a movie.
So, after I got entities and models being loaded into my resource managers, I figured I ought to do something with them. I'm going to replicate the loop in the 'game', though for the moment there's not going to be any even handling or much of a game state. Or actual rendering.
This structure fits within the 'Execution' method. After setting things up, within a while loop (with a suitable 'running' variable) I call a 'Render' method. The method should start with a ModelView matrix stack set to the Identity matrix. The projection matrix is set once and should not change unless something dramatic happens, like resizing the screen or changing the FOV, so it's not handled in here.
Then, we multiply the ModelView matrix by the View matrix, which represents the camera position. Then, we start calling the list of entities. For each entity, we add the model matrix to the stack, draw the entity, and pop the ModelView stack. This is it as far as rendering is concerned.
I don't really need to be concerned that I'm not working with OpenGL yet. Just handling the information back and forth should be enlightening. For example, I'm thinking I really need to keep everything together, no 'layers' really. They can be derived from different classes, but I can't isolate them based on it.
Games have a pretty standard structure. They're basically a loop, where you poll for input, update the state, and render to the screen. This loop runs dozens of times per second in a normal game. A game running at thirty fps is running through this loop thirty times per second. Each run is generally referred to as a frame, since you can consider the discrete changes in state between each run a snapshot, and the sequence of snapshots a movie.
So, after I got entities and models being loaded into my resource managers, I figured I ought to do something with them. I'm going to replicate the loop in the 'game', though for the moment there's not going to be any even handling or much of a game state. Or actual rendering.
This structure fits within the 'Execution' method. After setting things up, within a while loop (with a suitable 'running' variable) I call a 'Render' method. The method should start with a ModelView matrix stack set to the Identity matrix. The projection matrix is set once and should not change unless something dramatic happens, like resizing the screen or changing the FOV, so it's not handled in here.
Then, we multiply the ModelView matrix by the View matrix, which represents the camera position. Then, we start calling the list of entities. For each entity, we add the model matrix to the stack, draw the entity, and pop the ModelView stack. This is it as far as rendering is concerned.
I don't really need to be concerned that I'm not working with OpenGL yet. Just handling the information back and forth should be enlightening. For example, I'm thinking I really need to keep everything together, no 'layers' really. They can be derived from different classes, but I can't isolate them based on it.
Thursday, June 23, 2011
Back to the drawing board
Ugh, so annoying. I had the right idea in the previous posts with the design of the program, but I went a little too overboard with separating the functions of the different parts of the program. Too much insulation between the parts that manipulate my resources and the parts that read files. The problem being, there's too much interconnectedness in those two fields to have separated them so much.
It appears I'm going to have to fold the application layer into the resource layer. Otherwise, in order to load a model file, I have to break away from resource handling. Which is just dumb. Yeah, a link between layers would solve it, but it's poor form. If I need the connection to be porous between the two, I shouldn't be insulating them from each other so much.
Once I have things working together, I can reevaluate if I need to split them apart to clear up things. Overcomplicating things at the outset is never a good idea.
It appears I'm going to have to fold the application layer into the resource layer. Otherwise, in order to load a model file, I have to break away from resource handling. Which is just dumb. Yeah, a link between layers would solve it, but it's poor form. If I need the connection to be porous between the two, I shouldn't be insulating them from each other so much.
Once I have things working together, I can reevaluate if I need to split them apart to clear up things. Overcomplicating things at the outset is never a good idea.
Wednesday, June 22, 2011
Framework testing, reconsidered
It's usually easy to recognize bad code. It's big, clunky, ugly, and you hate writing it. It can get the job done, for certain values of 'the job' and 'done', but it isn't pleasant for anyone.
I had been struggling with part of my design, no matter how I looked at it I couldn't get it to do what I wanted it to. Not without creating a mess of code that was painful to look at. I've finally figured out that the problem was my design.
I had started well enough, separating tasks and delegating responsability. However, I went a bit too far down that path, to the point that I was hoping for classes at the bottom of the ladder to do too much. The class that handles the Entities, for example, should not be in charge of getting the entities' models loaded. In short, I was trying to make my classes too smart, and in trying to give them the freedom to act they had to learn about parts of the program that were beyond their scope.
So going forward, I'm going to be taking another look at how I am trying to handle this. The only 'upwards' communication the classes will have is answering queries by the holding object. No trying to start other jobs, just getting the specific function requested done, possibly returning a value as appropriate.
More tomorrow, when I start rambling on about what I'm trying to do again.
I had been struggling with part of my design, no matter how I looked at it I couldn't get it to do what I wanted it to. Not without creating a mess of code that was painful to look at. I've finally figured out that the problem was my design.
I had started well enough, separating tasks and delegating responsability. However, I went a bit too far down that path, to the point that I was hoping for classes at the bottom of the ladder to do too much. The class that handles the Entities, for example, should not be in charge of getting the entities' models loaded. In short, I was trying to make my classes too smart, and in trying to give them the freedom to act they had to learn about parts of the program that were beyond their scope.
So going forward, I'm going to be taking another look at how I am trying to handle this. The only 'upwards' communication the classes will have is answering queries by the holding object. No trying to start other jobs, just getting the specific function requested done, possibly returning a value as appropriate.
More tomorrow, when I start rambling on about what I'm trying to do again.
Project Demo, Reading a file
I'll scrap the interface bits out for now. The class holding the layers already holds the information I was trying to model with them, so it may have been redundant to try and store it as well inside each object. Instead I'll see what I need to get a file on request.
For starters, I need to configure the resource directories. For now, I'll store the "resource/model" directory in a std::string. I'll do the assignment in an initialization method. Then when asking for a given model, I only need to ask for the file name and it'll know where to look for it.
Reading a file is going to generally return a 'resource' of some kind. In this case a list of vertices that makes up the model. I'll store them in a vector. So for now, the ReadModel method will read a file and return a pointer to a vertices resource, which holds a vector of Vertex structs. Vertex contains 3 floats for coordinates, 3 for normal direction, and 2 for texture coordinates.
I'll use the c++ fstream libraries to handle the files, rather than Cs FILE. In the 'read' method, I'll create a ifstream object, and a string to build the full path. I'll then open the file (in read-only mode) and read the test 'triangle.tvl' file.
We now have a method for reading TVL files. Normally we'd need the model information when we created an Entity. The entity manager should know what kind of model each entity uses. When loading the entity, it should ask the model manager if the model is loaded.
This raises the question of how to refer to each model. This is something I'm not going to be happy with for a long time, so for now I'll use a number to refer to them. So our triangle will have the model id 0. Of course, now we need some way to store our entities as well. Which means another custom file format. And so is the TE (Text Entity) format born. For now, all it will have is the model id.
We quickly add another method in the application layer to read TE files and return Entities. We then add an int field to the Entity class and call it idModel, which is the single value to be read from the file. We also add a method to load the value into the field.
Ok, so now we can read the files, and the application layer returns pointers to the created objects. We need to add code to get the program to call those methods, though. We're trying to avoid building a whole program though. For the purposes of this demo, for example, the engine layer might as well not be there. We start with what would be the normal entry point of the program, the main function. There, we create a Game object. Once that is done, we should get the program going. We can call an 'Execute' method in game, which get the game going.
As soon as the game starts (within this execution method) we have to set the different layers up so they can be ready to work. For example, we have to set the resource paths we use in the Application Layer to read files. Eventually we'll have a configurable 'config.ini' type file that contains much of that information, but for now we'll just hard code the values in an initialization method for each layer.
So main calls game.execute, execute calls the application layer's initialization (the only one that needs to e initialized so far) and then.... Well, we could do a quick loop to simulate the normal running of the game. We load the first entity with a load entity function in the entity manager.... No. We try to get an entity. That would emulate what a method in the engine layer might try to do. So we ask for an entity... hmm. How do I ask for an entity? An entity id? But entities come and go. Normally the rendering engine just ask for a list of all entities that ned to be drawn. Well, entities do need to be 'created'. When the game starts it would create at the very least an entity to represent the player character. So we start with a 'create entity' method.
Hmm. Ok, so there could be a 'load resources' method in the resource layer as a way to initialize the bare necessities. This function would call a load function for each manager, or in the case of the entity, a create method. Ah, here we run into the problem with linking things together I scrapped before. The entity manager has a filename it wants to load, but the logic is over in the application layer.
Ok, at least I have a different perspective to assail this problem now. I want to have a good solution for this, since so much of the design depends on it.
And now I'm stuck again, thanks to the joys of the proper order for including files. I may have found a way around this, though.
For starters, I need to configure the resource directories. For now, I'll store the "resource/model" directory in a std::string. I'll do the assignment in an initialization method. Then when asking for a given model, I only need to ask for the file name and it'll know where to look for it.
Reading a file is going to generally return a 'resource' of some kind. In this case a list of vertices that makes up the model. I'll store them in a vector. So for now, the ReadModel method will read a file and return a pointer to a vertices resource, which holds a vector of Vertex structs. Vertex contains 3 floats for coordinates, 3 for normal direction, and 2 for texture coordinates.
I'll use the c++ fstream libraries to handle the files, rather than Cs FILE. In the 'read' method, I'll create a ifstream object, and a string to build the full path. I'll then open the file (in read-only mode) and read the test 'triangle.tvl' file.
We now have a method for reading TVL files. Normally we'd need the model information when we created an Entity. The entity manager should know what kind of model each entity uses. When loading the entity, it should ask the model manager if the model is loaded.
This raises the question of how to refer to each model. This is something I'm not going to be happy with for a long time, so for now I'll use a number to refer to them. So our triangle will have the model id 0. Of course, now we need some way to store our entities as well. Which means another custom file format. And so is the TE (Text Entity) format born. For now, all it will have is the model id.
We quickly add another method in the application layer to read TE files and return Entities. We then add an int field to the Entity class and call it idModel, which is the single value to be read from the file. We also add a method to load the value into the field.
Ok, so now we can read the files, and the application layer returns pointers to the created objects. We need to add code to get the program to call those methods, though. We're trying to avoid building a whole program though. For the purposes of this demo, for example, the engine layer might as well not be there. We start with what would be the normal entry point of the program, the main function. There, we create a Game object. Once that is done, we should get the program going. We can call an 'Execute' method in game, which get the game going.
As soon as the game starts (within this execution method) we have to set the different layers up so they can be ready to work. For example, we have to set the resource paths we use in the Application Layer to read files. Eventually we'll have a configurable 'config.ini' type file that contains much of that information, but for now we'll just hard code the values in an initialization method for each layer.
So main calls game.execute, execute calls the application layer's initialization (the only one that needs to e initialized so far) and then.... Well, we could do a quick loop to simulate the normal running of the game. We load the first entity with a load entity function in the entity manager.... No. We try to get an entity. That would emulate what a method in the engine layer might try to do. So we ask for an entity... hmm. How do I ask for an entity? An entity id? But entities come and go. Normally the rendering engine just ask for a list of all entities that ned to be drawn. Well, entities do need to be 'created'. When the game starts it would create at the very least an entity to represent the player character. So we start with a 'create entity' method.
Hmm. Ok, so there could be a 'load resources' method in the resource layer as a way to initialize the bare necessities. This function would call a load function for each manager, or in the case of the entity, a create method. Ah, here we run into the problem with linking things together I scrapped before. The entity manager has a filename it wants to load, but the logic is over in the application layer.
Ok, at least I have a different perspective to assail this problem now. I want to have a good solution for this, since so much of the design depends on it.
And now I'm stuck again, thanks to the joys of the proper order for including files. I may have found a way around this, though.
Subscribe to:
Posts (Atom)